ロードマップでわかる!当世プロセッサー事情 第674回
Zen 5に搭載するAIエンジンのベースとなったXilinxの「Everest」 AIプロセッサーの昨今
2022年07月04日 12時00分更新

AI Engineを1GHzで稼働させれば
51.2T Ops/サイクルの処理性能になる
さて、AI/機械学習に関して言えば、活性化関数の処理などに関してはScalarユニット(つまりRISCプロセッサーの方)で行なう(“Non-linear Functions”がまさにこれに向けたものと思われる)。逆に言えばAI/機械学習での計算処理のほとんどを占める畳み込みや全結合などの処理はVectorユニットの方で行なわれることになる。
そのVectorユニットの性能が下の画像になる。512bit幅のSIMDエンジンで、一番簡単な8bit real(8bit整数)同士の乗加算なら1サイクルあたり128個を処理できる。
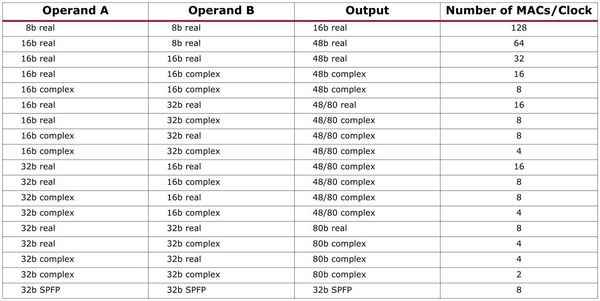
Vectorユニットの性能。SPFPはSingle Precision FP、つまり単精度の浮動小数点演算である
一番遅いのが32bit complex(32bitの複素数)同士の演算で出力が80bitのComplexでは1サイクルあたり2個にまで減るが、そもそもcomplexの処理はAI/機械学習では利用されず、主にワイヤレス向け(無線で使われる変調方式などで多用される)ということなので、実際にはreal同士の演算がメインと考えれば良い。すると1つのAI Engineあたり128 Ops/サイクル、これが最大400個だと51200 Ops/サイクルほどになる。
仮にこのAI Engineを1GHzで稼働させれば、51.2T Ops/サイクルという猛烈な処理性能になるわけで、確かにAI向けとしては悪くない性能である。もともとXilinxはAI学習の市場には手を出さず、推論のみに展開する予定だったので、これは十分な性能と言える。
ちなみにAI Engineそのもののデータメモリーは1個あたり32KBなので、400個集めても12.5MBでしかなく、これで足りるか? と言うとけっこう厳しいのは事実だが、実際にはFPGA側にもSRAMがあり、これをL2 SRAMとして利用可能であり、さらに外部にDRAM(DDR/HBM)を接続可能になっている。
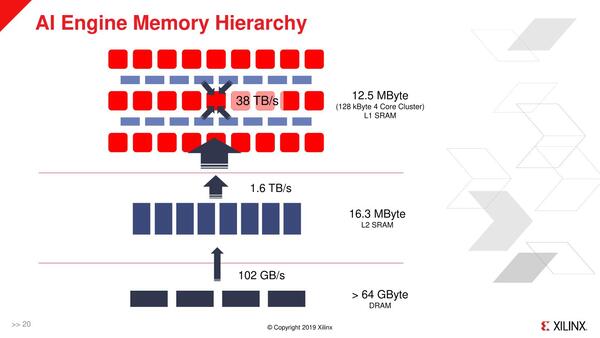
最大構成では、32KB BlockのSRAM×463個と4KB BlockのSRAM×967個をAI EngineのL2 SRAMとして活用できる。帯域も1.6TB/秒と大きいので、利用できるメモリーが最大で28MBほどあると考えてもそう間違いではないだろう
これだけあれば普通に使うにはまず困らない、という判断と思われる。実際GoogleNetやResNetでの結果を見ると、AI専用プロセッサーに引けを取らない性能を出しているのがわかる。
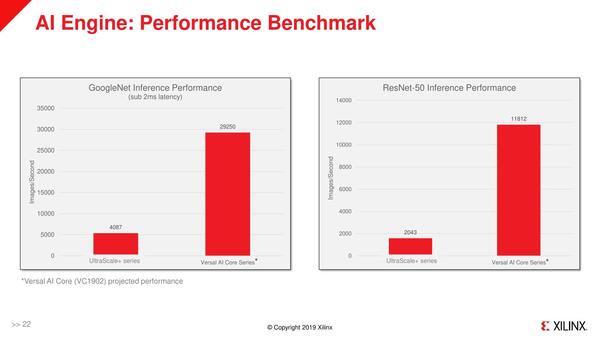
GoogleNetやResNetでの結果。比較対象がXilinxの前世代のFPGAなのは仕方がないところだ
第2世代になり演算器とメモリーが倍増
ピーク性能は初代AI Engineの4倍に
このAI Engineであるがこれはいわば第1世代にあたる。というのは2021年6月にXilinxがVersal AI Edgeという製品を出した時には、第2世代のAI Engine-MLに進化した。

第2世代のAI Engine-ML。メモリーも倍増されたほか、AI Engine側に新たなメモリーブロックが追加されたようにも見える
基本的な構想そのものは変わっていないが、以下のようにけっこう大規模なものである。
- 演算器を倍増。おそらく固定小数点SIMDを廃し、代わりに浮動小数点SIMD×2とした。またVILW命令も変更され、Vector Operationを同時2つ発行可能にしたと思われる。これにともない、ロード/ストアーも帯域を倍増させたほか、Vector Register Fileの数も増やしたと考えられる。
- Int 4/Bfloat 16をサポート。これにより、Int 8の場合の2倍の処理性能が確保された。
NVIDIAのJetson Xavier NXとの比較が下の画像である。ピーク性能が4倍のわりにそれほどでもないのでは? と言うのは、AI Engine-MLの数が異なるためである。

絶対的な数値が出ていないので判断が難しいが、ラフに言えばピーク性能は初代AI Engineの4倍になったわけで、あとは構成次第である。ちなみに結果はVE2102/VE2302/VE2802と、違った構成の製品で比較しているのにも注意
下の画像が発表時の構成であるが、VE2102は12個、VE2302は24個、VE2802で304個、とAI Engine-MLの搭載数が大きく異なる。
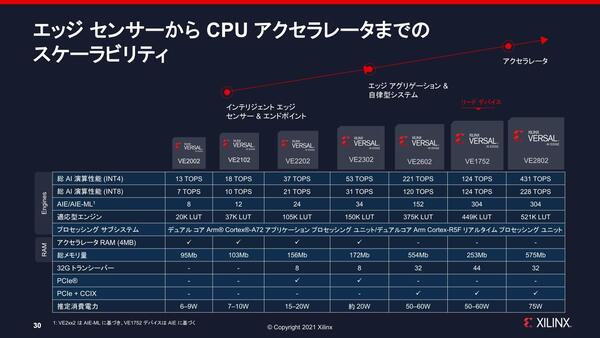
VE2xx2のみがAI Engine-MLを搭載しており、VE1752はAI Engineなのに注意。なので個数が同じ304にも関わらず、VE2802の半分強の性能でしかない。きっちり半分にならないのは、動作周波数の違いと思われる
ただかなりローエンドに近いVE2102では12個しかAI Engine-MLが搭載されていないのにINT4での演算性能は18TOPSで、Jetson Xavier NXと比べて性能/消費電力比が1.9倍というのは、FPGA以外にこれを持ち込もうというのには有望そうに見える。
もちろんAI EngineとAI Engine-MLではバイナリー互換性はまったくないが、このあたりはコンパイラが吸収してくれるのであまり問題はないという返事が返ってきた。
ただ今後Zen 5世代ではCPUにもこれが入るあたりでは、製品ごとの差(おそらくAI Engine-MLのみが搭載されることになると思うが、AI Engine-MLのコア数まで全SKUで一緒かどうかはわからない)を再コンパイルの手間なしに吸収するためのなにらかの仕組みが用意されることになると思われる。連載671回の最後で紹介したUnified AI Stack 2.0の、Windows RuntimeやLinux Runtimeがこのあたりを吸収する形でバイナリー互換性を取る格好ではないかと思われる。
連載657回で触れたが、Raptor LakeにはMyriad X VPUを外付けで接続するための専用M.2スロットが用意されるようだ。さらにこれに続くMeteor Lakeでは、第3世代のMyriad VPUが今度はチップ内に統合されるようだ(SoC Tileに実装されると思われる)。
Xilinx由来のAI Engine-MLは、このMyriadシリーズVPUの対抗馬という位置づけになるわけだが、両社のNPUで共通に使えるようなAPIが構築される、という話がまったく聞こえてこないあたり、なんとなくビデオエンコード/デコードアクセラレーターと同じような扱い(アプリケーションの側でAMD Media Encoder/Intel Media SDK/NVIDIA NVEncにそれぞれ個別対応)になりそうな感じがある。
ややユーザーには不便な感じであり、マイクロソフトあたりがなにかしら共通API(DirectX AIなど)を作ってくれるとうれしい限りだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ












