




Sapphire Rapidsの構成が判明
タイルの面積は約400平方mm
詳細な構成(コア数やSKU)は製品出荷のタイミングで公開する、という話で一切説明はなく、性能という意味ではAMXの性能や、Microserviceでの性能がCascade Lake比で69%向上すると説明しているが、Ice Lake-SP比だと37%程の向上でしかない辺りは少し「?」ではある。

これは実際の性能というよりは、AMXを利用した場合の理論性能をAVX512と比較しただけである

Microserviceでの性能がCascade Lake比で69%向上するという。こちらもシミュレーションで、しかもなにをどう比較しているのか不明である
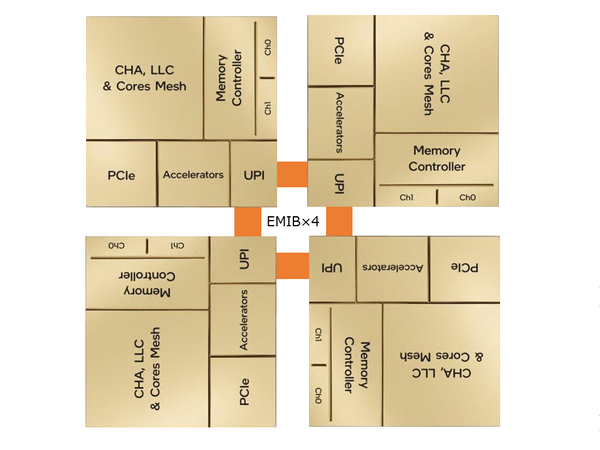
Hot Chipsのカンファレンスセッションでの情報はこの程度であり、メモリーコントローラー周りやPCIe/HBMに関する話は連載629回のスライドで示したものそのままなのだが、カンファレンスに先立って行なわれたチュートリアルセッションでびっくりの情報が出てきた。これはインテルのパッケージ技術の紹介で、実際の製品の構成を説明するものだが、EMIBの実装例としてSapphire Rapidsの構成が出てきた。

先にSapphire Rapidsのタイルの面積が約400mm2と書いたが、根拠はこのスライドである
ここから以下のことが読み取れる。
- (1)HBMの有り無しでパッケージが異なる
- (2)HBM無しの場合であっても、4つのタイルの接続に10個のEMIBが使われている
それともう1つ、カンファレンスセッションの質疑応答で以下のことも確認された。
- (3)HBMコントローラーとDDR5のコントローラーは別になっている
まず問題になるのが(2)だ。前述のSapphire Rapidsの構成画像を見る限りEMIBは4つであるので、下図のような配置で接続されると想定していた。
筆者が想定していたSapphire Rapidsの配置図
この場合、内部は下の図になるという想定だ。各々のタイルから3本づつUPIが出て、うち2本はタイル間の接続に、残る4本が外部接続に利用される格好だ。

筆者が想定していたSapphire Rapidsの内部構成
これはこれで筋が通ってはいるのだが、EMIB×10だとすると辻褄がまるで合わなくなる。となると、やはり実際には下図のように斜め方向のUPI接続も行なわれている可能性が高い。

斜め方向のUPI接続を加えた配置
構造で言えば下図のような形だ。

斜め方向のUPI接続を加えた構成
問題は、EMIBでどうやってこの斜めの交差を実現するか? である。これに関してまだ明確な説明はなされていないのだが、筆者が考えた案の1つは下図のような立体交差だ。

筆者が予想する、斜めの交差を実現するための立体交差案
Tikle 1とTile 4は通常の埋め込み型EMIBを取り、Tile 2と3の間は中にEMIBを仕込んだ立体構造のブリッジを構築、これでつなぐという仕組みである。これが合っているかどうかは定かではないが、10個というEMIBの数を考えるとなにかしらトリックがあると思われる。このあたりは製品発表時に情報が公開されるのではないかと思う(というか、期待したい)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























