




前回は細かい話を全部飛ばして、大枠での説明だったので、今回からもう少し細かく説明していきたい。まず今回はAlder Lakeに関する話だ。
さて、HotChipsでは、Alder Lake自身やそのコンポーネントであるP-Core/E-Coreに関する詳細はほとんど説明がなく、唯一Thread Directorに関してのみ突っ込んだ話があった。したがって、主にArchitecture Dayのスライドを使いつつ、要所のみHotChipsでのスライドを使いながらご紹介説明したい。
第12世代デスクトップ向けマイクロプロセッサー
Alder Lake
Alder Lakeの構成そのものは前回も紹介した。下の画像はデスクトップ構成のものだが、最大16コアで、P-Core×8、E-Core×8である。ただハイパースレッディングはP-Coreのみ有効とされ、E-Coreはハイパースレッディング無効の状態で実装される。つまり、システム全体としては最大24スレッドになる。

SKUによっては、例えばCore i5はP-Core×6+E-Core×8、Core i3はP-Core×4+E-Core×8といった形になるが、ダイそのものは共通な模様
もう1つおもしろいのはLLCが最大30MBになったこと。前回掲載したAlder Lakeの構成図にもあるように、それぞれのP-Coreと、4コアのE-Coreクラスターにそれぞれ1つづつのLLCが組み合わされる形となるので、LLCそのものは1個3MBになる。
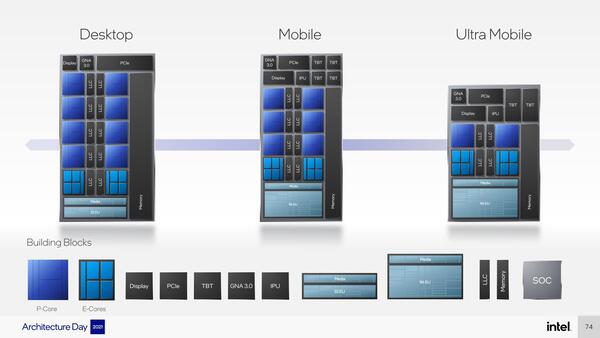
前回掲載したAlder Lakeの構成図。P-CoreとE-Coreクラスターにそれぞれ1つづつLLCが組み合わされる
ちなみにこのLLCはP-CoreとE-Core、およびGPUからもアクセス可能になっており、システム全体で共有できるという話であった。
次にインターコネクト。内部のインターコネクトは最大1000GB/秒にも達する。I/O Fabricの64GB/秒というのは、前回のPCIe構成図で説明したようにPCIe Gen5 x16レーンが出るからである。
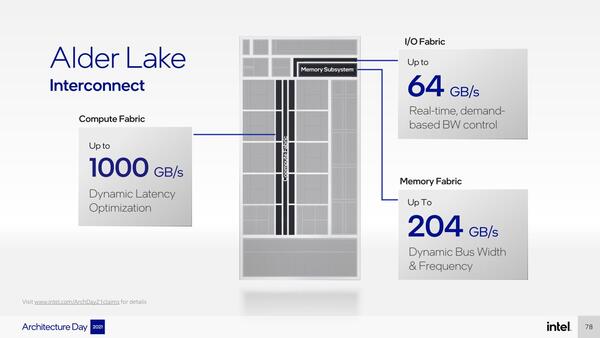
インターコネクトは最大1000GB/秒にも達する。ちなみに構造はRing Busなのは相変わらず。おそらくはTiger Lake同様のDual Ringと思われる
PCIe Gen5は転送速度が32GT/秒なので1レーンあたり4GB/秒、x16レーンで64GB/秒という計算である。もっとも現状、まだPCIe Gen5対応GPUが存在していない以上、やや宝の持ち腐れ感はある。ちなみにPCHとの接続が、DMI 4.0ベースなのか、DMI 3.0×2構成なのかはまだはっきりしない。
さて、Alder LakeではP-CoreとE-Coreが載るわけだが、Architecture DayではE-CoreはSkylakeとの比較、P-CoreはCypress Cove(Rocke Lake)との比較で、今ひとつ全体としての性能がわからなかった。今回HotChipsではE-CoreとP-Coreの性能比較が示された。
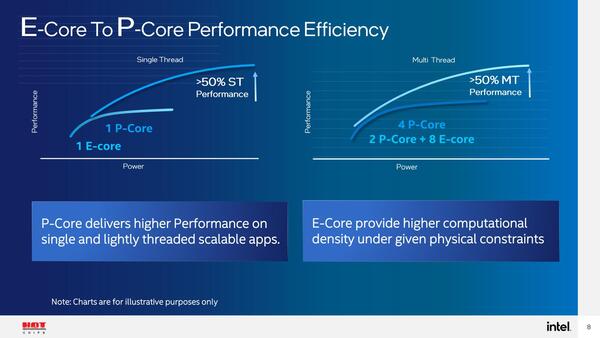
E-CoreとP-Coreの性能比較。右側のグラフからすると、P-Core×1とE-Core×4がほぼ同等の消費電力で、しかもトータルでの性能はE-Core×4の方が高いことになる
これを一見してわかるのは、予想以上にE-Coreが省電力方向に振っていることだ。この後説明するが、E-CoreはTremontと比べてもかなりゴージャスというか、そもそもSkylakeと比較してもIPCが高めとされていたし、それそのものは事実だろう。実際バックエンド側はSkylakeを超える規模になっているから、IPCが向上していることそのものは不思議ではないが、普通にこれを実装すれば、Skylakeと同等以上のエリアサイズになる。
ところが実際E-CoreはP-Coreよりもずっと小さい。まだダイサイズの写真などが公開されていないので正確なところは不明だが、本記事冒頭の図ではE-CoreはP-Coreの1/4以下の面積でしかない。もちろんこれは正確な比率ではないと思うが、Mobile/Ultra Mobileでは1つのP-Coreをほぼ4つのE-Coreで置き換えている形になっていることを考えると、相当小さいことは間違いない。
回路規模が相応に大きく省電力で動き、しかもプロセスそのものはP-Core同様にIntel 7が利用されるという話であれば、実装としては以下のあたりが思いつく。
- 利用するトランジスタの種類が、高密度・省電力向けのものを使っている
- パイプラインの一つのステージに、かなり多くの回路を突っ込んでいる
トランジスタの種類を変えられるのか? と言われそうだが、例えばFinFETの構造そのものは同じであっても高速回路向けにはFinの数を増やして駆動電流を増やすのが一般的なので、逆に1Finだけで構築すれば動作速度は落ちるものの消費電力は減るし、エリアサイズも削減できる。
ただこうした結果として、E-Coreのベストな性能はP-Core最低動作周波数程度に落ち着くことになる。おもしろいのは、P-Coreでマルチスレッド性能を追求しようとするとどうしても動作周波数を上げざるを得ないし、そうなると効率は急速に落ちる。逆にE-Coreを大量に動かしても、動作周波数を低めに抑えることで消費電力はそれほど上がらないため、マルチスレッド系の処理性能効率は上がるというわけだ。なかなかおもしろい特性である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ






































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












