




グラフ理論の処理に特化したGSPの仕組み
ということで話をGSPに戻す。GSPは巡回セールスマン問題のような複雑な処理をすることは考えていないが、計算機の世界ではこうしたグラフ的に表現される処理が多数ある。
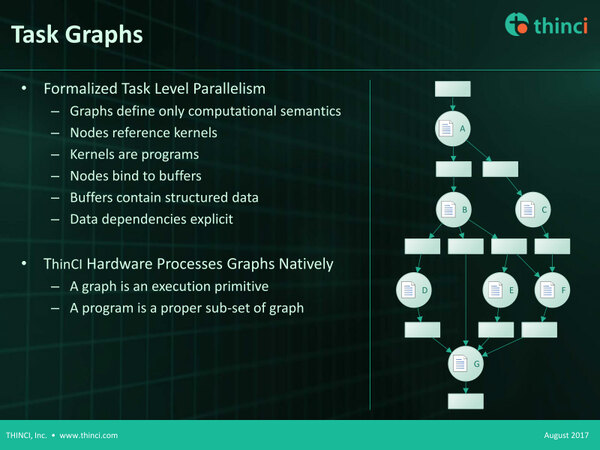
グラフ的に表現できる処理の一例。ここで言えばA~Gまでが個々の処理ということになる。間の四角はバッファである。
これを効率的に実行できるようにしよう、というのがGSPである。このGSPをDSPやGPUなどと対比させた例が下の画像である。

GSPをDSPやGPUなどと対比させた例。単にバッファが小さくなったというわけではなく、バッファが最小限で済むようになった点がポイントである。それはともかく左下の図はやや間違っている気がする(Node BとCは並行して動くはず)
この例で言えばNode A~Node Dが計算処理ということになる。さて、DSPやGPU、つまり左側であるがここではまずある程度のデータの塊(画像処理なら64×64ピクセルなど、そういうある程度の単位)をNode Aで処理し、その結果が1と2のバッファに蓄えられる。
それが終わったら、次にNode BとNode Cが動く。Bは1から結果を読みこんで、処理結果を3と4に、Node Cは2から結果を読みこんで、処理結果を5に蓄える。
最後にNode Dが3~5から結果を読み込んで処理し、6に吐き出す形だ。ここでネックになるのは、Aが処理を終わるまでBとCの処理が始められないし、BとCが終わらないとDが始められないことだ。
もちろん、例えば「1と2のバッファのここからここまでデータを入れ終わった」と、Node AからNode B/Cにこまめに通知すれば、Node Aが完全に0のデータを読み切って処理を終わる前にNode B/Cの処理を開始することは不可能ではないが、今度はそうした通信のオーバーヘッドが極端に大きくなりすぎる。
Node Aが64×64ピクセルの画像を4×4ピクセル単位で処理すると仮定すると、256回処理すると完了であり、仮に1回の計算が1サイクルで終了するとしても、Node Aが256サイクル稼働後に1と2に結果を吐き出し、これを受けてNode BとCが並行してやはり256サイクルかけて処理し、3~5を出力。最後にNode Dが256サイクルかけて6を出力するので、合計768サイクル必要になる計算になる。
GSPではこれをもっとスマートにできる。GSPのS、つまりStreamであるが、Stream(流れ)というように、内部のプロセッサーコア(つまりNode A~D)はもっと細切れで処理が可能になっている。
端的に言うと、Node Aが最初の1回の計算をしたら、その結果は直ちに1と2のバッファに書き込まれる。これが書き込まれたら、次のサイクルにはNode BとCが動き始め、その1サイクル後には結果が3~5に書き出される。
最後にNode Dが動いて1サイクル後に結果が6に保存されるわけで、Node Aが動き始めてから3サイクル目には最初の結果が出力されることになる。所要時間はトータルで259サイクル(3+256サイクル)で済むわけで、左の方式よりも3倍高速というわけだ。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")



























")













