




プロトタイプはTSMCの28nm HPC+プロセス
実際のGSPの内部構造が下の画像である。2017年の発表時点では、個々のプロセッサーの詳細は説明されていない。

GSPの内部構造。個々のプロセッサーは1スレッドを実行するシンプルなものの模様。ただ具体的な演算能力などは不明
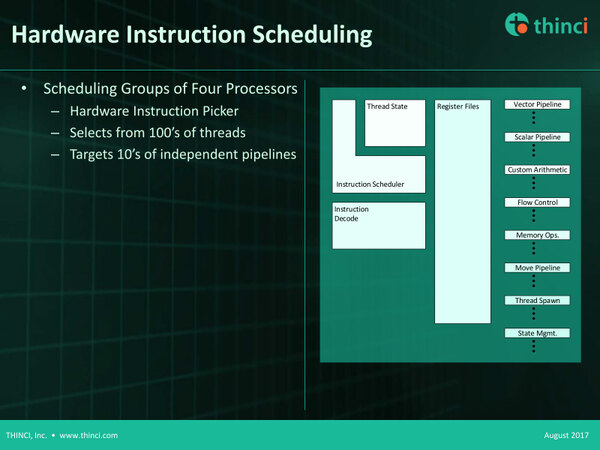
個々のプロセッサーの概略。これだけみると、Single IssueのIn-Orderの構成になっているように見える
全体としてみると、4つのプロセッサーコアを搭載するQuadという処理単位が複数個並び、その外側に2次/3次キャッシュが付く構造になっている。特徴的なのは以下のとおりで、トポロジー(構造)に特に制約は設けられていない。
- 全体のスレッドスケジューリングは、Quadの手前のThread Schedulerで処理される。
- Thread Schedulerはデータ依存性を理解し、実行リソースが利用可能で入力データが用意されているスレッドを選んで、個々のQuad内のプロセッサーに割り当てる
- リダクション命令が用意される。要するに複数要素を一つにまとめて結果を出すというもので、Convolutionにおける総和がまさしくこの例となる。これが並列に実行できるので、総和の計算(1回のConvolutionに必ず1回発生する)を大幅に高速化できる
- システム全体では、平均100あまりのスレッドがIn-Flight(稼働可能)状態に保たれ、そこから数十(これはQuadの数次第)のスレッドが並列実行される
- 原理的にGSPというか個々のプロセッサーでは、扱うデータタイプや精度、グラフのトポロ・Streamデータではなく、長期間滞在するデータ(例えばConvolutionの計算の際の総和)に対し、2次元配列としてアクセスする機能を持つ。これはメモリーアライメントと無関係にアクセス可能
- メモリーに対して2次元アクセスが可能
2017年の発表時にはTSMCの28nm HPC+プロセスを使って試作されており、スタンドアロンのPCIeアクセラレーターとSoC内部の組み込みの両方が可能ながら、SoCモードでは2.5Wで動作するという見積もりがなされていた。
ただこの時点では性能そのものは公開されておらず、2.5WはともかくとしてどこまでAIのアクセラレーターで使い物になるのかは未知数という評価だったと記憶している。
おそらくまだプロトタイプだったためもあるのだろう。ダイにブルーでマスクが掛けられており、これだともうなにがなんだかという感じ
DFPのWave Computingと同じ
Tailwood CapitalがThinCIに出資
ここで冒頭の話に戻る。デンソーは2016年にまずThinCIに出資しているが、2018年には追加出資している。またNSI-TEXEの設立は2017年9月であり、そこからDFPの開発をスタートしているわけで、中核にはこのGSPのグラフ制御の技術があったものと推察される。
実際GSPのストリームプロセッサーという構成そのものは、限りなくData Flow Processorに要求される方式そのものである。余談であるが、Data Flow ProcessorといえばAIの世界ではWave ComputingのDFPがいろいろな意味で有名であるという話を連載568回でした。
Wave ComputingはTailwood Capitalが出資者であり、それもあってTailwood CapitalのマネージングパートナーであるDado Banatao氏がWave Computingの会長を務めているわけだが、実はThinCIにもTailwood Capitalは出資しており、それもあって同社の取締役にもBanatao氏が名前を連ねているあたりがなんとも、という感じである。
ついでに言えばBanatao氏の名前が最初に出てきたのは連載20回。実はS3の創業者であり、また連載381回では触れていないが、C&Tの創業パートナーでもある。根っからの起業家体質の方で、その意味ではWaveは失敗だったのだろうが、立ち上げた会社が全部成功するわけでもないだろうから、そのあたりは割り切っているのかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")















