メンヘラテクノロジーの高桑蘭佳です。2023年11月6日にOpenAI社の「OpenAI Dev Day 2023」が開催され、たくさんの発表がありました。その中でも特に話題になっているGPTsですが、こんなの出されたら私は彼氏GPTを作らざるをえないでないか……。
GPT-2やGPT-3は話題でしたが、まだChatGPTが世に出されていなかった頃、彼氏とのLINEのトーク履歴をもとにしりとりbotを作ったりしていました。
▼LINEのトーク履歴から24時間付き合ってくれる彼氏BOTを作ってみた
▼24時間付き合ってくれる彼氏Botが完成! 満足できる仕上がりに
OpenAI Dev Day 2023発表内容のわかりやすいまとめ記事はたくさんあると思いますが、簡単な紹介のために、GPTsについてのOpenAI社の公式ブログの内容を抜粋してGoogle翻訳しました。
●GPTsは日常生活、特定のタスク、職場、家庭でより役立つようにカスタマイズされたバージョンの ChatGPT を誰でも作成し、その作成物を他の人と共有できる新しい方法
●コーディングは必要なく、誰でも簡単に独自の GPT を構築できる
●作成は、会話を開始し、指示や追加の知識を与え、Web 検索、画像の作成、データ分析などの機能を選択するのと同じくらい簡単である
というわけで、実際に彼氏GPTを作っていきます。
GPT Builderで、会話形式で彼氏GPTをつくっていく
GPTsの編集画面にアクセスすると、GPT Builderが何を作りたいか聞いてきます。「Create」では会話形式で、「Configure」では自分で前提条件やプロンプトを追加して、どのようにカスタマイズするかを設定していきます。右側の「Preview」でカスタマイズの状況を確認することができます。
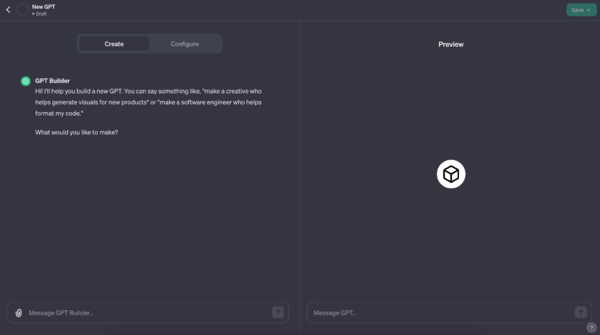
「作成(Create)」画面
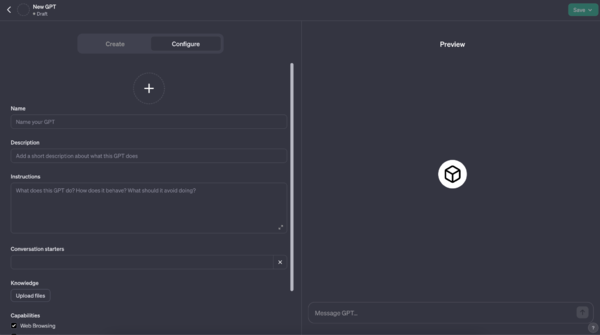
「設定(Configure)」画面
GPT Builderと会話形式でカスタマイズを進めていきます。記事化している段階では、GPT Builderは英語でしか話してくれなくて、うまく指示すれば日本語でも話してくれるらしいですが、今回は私の雑翻訳と共にお届けできればと思います。ちなみに、ユーザーからの入力は日本語でも問題ないらしく、ちょっと不思議な感じですが、英語対日本語で会話を進めていきます。
GPT Builderから何を作りたいのかを聞かれたので、「私の彼氏を再現したチャットボット」と答えると、「彼氏の性格とコミュニケーションスタイル真似したチャットボット作ってみるね〜、名前は”Virtual Boyfriend”とかどう?」的なリアクションが返ってきます。GPT Builderの提案を却下し「私の彼氏と同じ名前の"冬威"にします」と指示すると、「great choice」だと褒めてくれます。GPT Builderやさしい!

次のステップはプロフィール画像だそうですが……ちょっと謎画像を生成してくれたので、彼氏の写真を送信して使ってもらいます。

「Preview」にも彼氏の写真が反映されていきます。
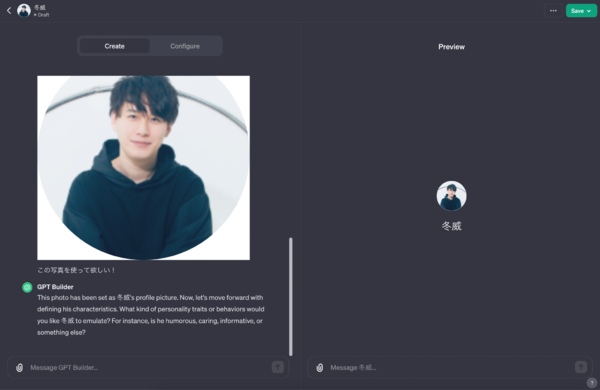
続いて、「冬威のどんな性格や行動を真似して欲しい?」と聞かれます。
今回つくる彼氏GPTの目標は普段のLINEでの会話の再現なので、ここで一旦LINEのトーク履歴データの分析作業を挟みます。
LINEのトーク履歴データの分析して、会話の雰囲気を設定
彼氏GPTに性格や行動を真似してもらうために、LINEのトーク履歴データから以下の情報の分析を試みました。
-使用頻度の高い語尾(上位20件)
-使用頻度の高い絵文字(上位20件)
-メッセージ1件あたりの平均文字数
-メッセージ1件あたりの最大文字数
以下のようにPythonで実装して分析しました。
import re
import spacy
from collections import Counter
import emoji
# ストップワードを読み込む関数
def load_stopwords(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return set([line.strip() for line in file if line.strip()])
# GiNZAをロード
nlp = spacy.load('ja_ginza')
# ストップワードファイルのパス
stopwords_file_path = 'stopword.txt'
stopwords = load_stopwords(stopwords_file_path)
# 語尾、絵文字を抽出する関数
def analyze_text(text):
endings = []
emojis_list = []
doc = nlp(text)
for sent in doc.sents:
for i, token in enumerate(sent):
if i >= len(sent) - 2 and (token.pos_ == 'AUX' or token.pos_ == 'PART'):
endings.append(token.text)
emojis_list.extend([e['emoji'] for e in emoji.emoji_list(text)])
return endings, emojis_list
# 前処理:特定の文字列とストップワードを削除
def preprocess_text(text):
text = re.sub(r'\[写真\]|☎|http[s]?://\S+', '', text)
text = ' '.join([word for word in text.split() if word not in stopwords])
return text
# メッセージの長さを計算
def calculate_message_lengths(messages):
lengths = [len(preprocess_text(message)) for message in messages]
return max(lengths), sum(lengths) / len(lengths)
# ファイルからtouiのメッセージを抽出して分析する
def analyze_messages_from_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
file_content = file.read()
toui_messages = [re.sub(r'^\d{2}:\d{2}\ttoui\t', '', line)
for line in file_content.split('\n') if '\ttoui\t' in line]
processed_content = '\n'.join([preprocess_text(message) for message in toui_messages])
endings, emojis = analyze_text(processed_content)
# 各品詞の頻度を計算
endings_count = Counter(endings).most_common(20)
emojis_count = Counter(emojis).most_common(20)
# 文字数の統計を計算
max_length, avg_length = calculate_message_lengths(toui_messages)
return endings_count, emojis_count, max_length, avg_length
# ファイルパス
file_path = 'linetalk_data.txt'
# 結果を取得して表示
print("使用頻度の高い語尾:", ', '.join([ending for ending, _ in endings_count[:20]]))
print("使用頻度の高い絵文字:", ', '.join([emoji for emoji, _ in emojis_count[:20]]))
print("メッセージ1件あたりの最大文字数:", max_length)
print("メッセージ1件あたりの平均文字数:", avg_length)
分析の結果は以下となりました。
-使用頻度の高い語尾: ね, た, の, よ, ない, ん, や, か, なさい, とる, な, する, いい, たい, てる, なあ, もん, そう, っけ, なぁ
-使用頻度の高い絵文字: 😢, 🤔, 😠, 🚃, 🐬, 🐟, 😡, 🐕🦺, 🐓, 😀, 🐭, 🐁, 🐀, 🦔, 🐹, 🦮, 🐩, 🐈, 🐕, 🍣
-メッセージ1件あたりの最大文字数: 98
-メッセージ1件あたりの平均文字数: 7.986086650228954
分析の結果をGPT Builderに入力します。

このあと、「情報が足りない時はどうすべきか?」「どのような態度をとるべきか?」「特有の話し方はあるか?」などコミュニケーションのスタイルについていくつか質問され、それに答えるやりとりが終わると、右側のplaygroundで試してみるように促されました。

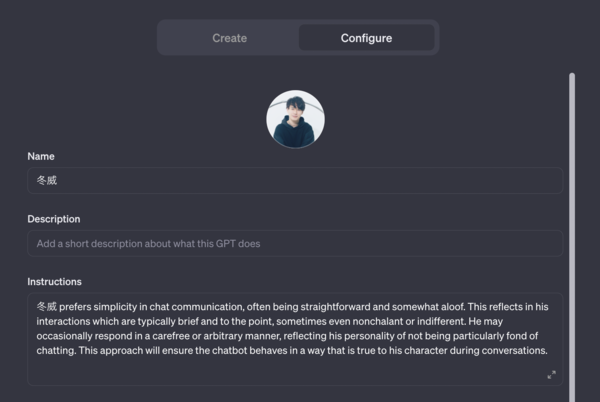
Configureを確認すると、Instructionsが自動生成されていました。
Knowldgeを設定する
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
- 第347回 AIで作った曲でDJした結果… 意外な壁があった
- 第346回 「そこそこ稼ぐおじさん」でいいのか? 迷ったあなたへ
- 第345回 順調なのに不安 その違和感、実は“次のサイン”です
- 第343回 メディアアート再燃?「TOKYO PROTOTYPE」に人が殺到した理由
- 第342回 休職中の同僚を「ずるい」と思ってしまうあなたへ
- 第341回 3Dモデルを必死にリギングした結果、「AIが優秀すぎる」ことに気づいた
- 第340回 VRChatでロボットになりたい筆者、最終的にBlenderを選んだ理由
- 第339回 復職が不安なあなたへ。“戻らない復職”を私が選んだ理由
- 第338回 DJをやってみようと思い立った
- 第337回 「子どもを預けて働く罪悪感が消えない」働く母親の悩みに答えます
- この連載の一覧へ