




前回に引き続きTSMCの発表から。今回は次世代のSoICに向けた取り組みの話となっているのだが、その前に連載810回の補足をしたい。
IEDMに続き、今年の2月16日からISSCC(International Solid-State Circuits Conference) 2025がサンフランシスコで開催された。もっとも本番は月曜の2月17日からで、初日の2月16日はフォーラムおよびチュートリアル・セッションのみの開催である。
TSMCのSRAMテストチップにおける欠陥密度を再計算
比較的順調なのがわかった
実は今年のISSCC、Plenary SessionsでPat Gelsinger氏の講演があるはずだったのが、CEO職辞任にともないインテルのNavid Shahriari氏(SVP, Foundry Technology Development)が代わりに講演を行なったりした。このISSCCのSession 29のテーマがSRAMで、TSMCとインテル、MediaTek、Synopsysの4社が5つの発表をしている。
TSMCは2件あり、1つは"29.5 A 3nm 3.6GHz Dual-Port SRAM with Backend-RC Optimization and a Far-End Write-Assist Scheme"というもの。もう1つが"29.1 A 38.1Mb/mm2 SRAM in a 2nm-CMOS-Nanosheet Technology for High-Density and Energy-Efficient Compute"となっている。
この29.1で、TSMCのSRAMテストチップのイメージが公開された。連載810回ではSRAMのテストチップの様子がわからなかったので適当に推定したのだが、もう少し厳密に欠陥密度を計算できそうである。
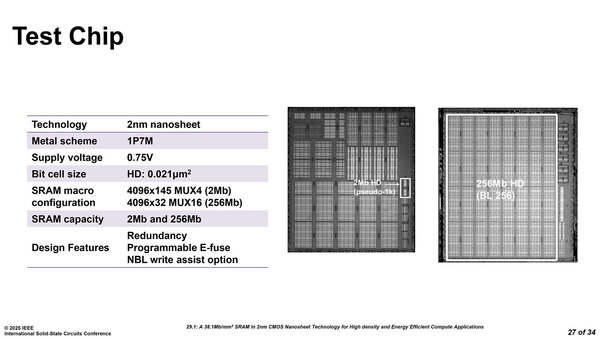
左のものは2Mbit SRAMのテストチップ、左が256Mbit SRAMのテストチップである
下の画像は上の画像のテストチップを拡大したものだ。ここで黄色で示した部分が実際のSRAMセルの部分であり、塗りつぶしていないのは縦横の配線となる。

HD(High Density)とはいえ、結構配線が占める面積が大きいのがわかる
Bit cell size(1bit分のSRAMセルの面積)は0.021μm2となっているので、これを256Mbit分集積した面積(つまり上の画像の黄色の面積の合計)は5.673mm2ほどになる。一方でテストチップ全体の大きさは4.24×4.70mmで19.95mm2ほどと推定される。
この寸法を元に欠陥密度を推定してみた。SemiAnalysis Die Yield Calculatorで試算すると下表になる。
| 欠陥密度と歩留まりの関係 | ||||||
|---|---|---|---|---|---|---|
| 欠陥密度 | 歩留まり | |||||
| 0.1 | 98.03% | |||||
| 0.2 | 96.11% | |||||
| 0.3 | 94.22% | |||||
| 0.4 | 92.39% | |||||
| 0.5 | 90.60% | |||||
| 0.6 | 88.84% | |||||
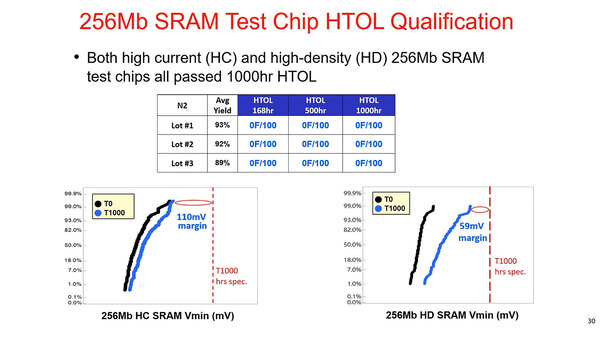
下のスライドによれば、Lot #1~#3の3つの製造ロットにおける平均の歩留まりは93%、92%、89%ということだから、Lot #1は欠陥密度が0.4個弱/cm2、#2は0.4個強/cm2、#3は0.6個弱/cm2ということになる。多少まだバラつきは見られるが、おおむね0.4個/cm2前後の欠陥密度をすでに実現していると考えて良さそうだ。したがってTSMCのN2はやはり順調そうである、と言えるだろう。
次世代のSoICではおおむね2倍の帯域をほぼ同等の電力で利用できる
さて今回のお題は「HPCアプリケーション向けとなる次世代のSoIC」である。HPCと言っても、実際にはAIだったりするのだが、特に2018年あたりから言語モデルの利用によって急速に性能への要求が高まり、この結果必要となるトランジスタの数も増える。
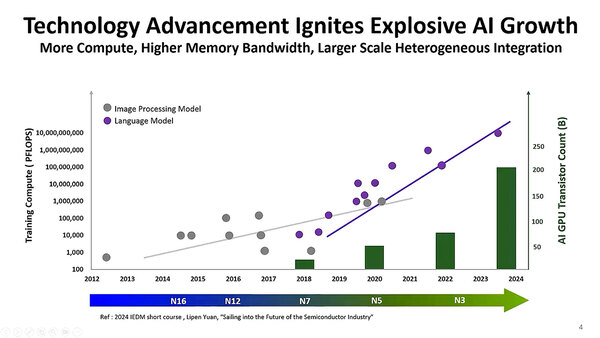
問題はトランジスタの数を無尽蔵に増やせるわけではないことだ
といっても、チップとして製造するためにはReticle Limitというものがあって、どうがんばっても800mm2を超えるようなチップは製造できない(し、このサイズでは歩留まりが相当悪化する)から、結局複数チップに分割して間をつなぐことになる。
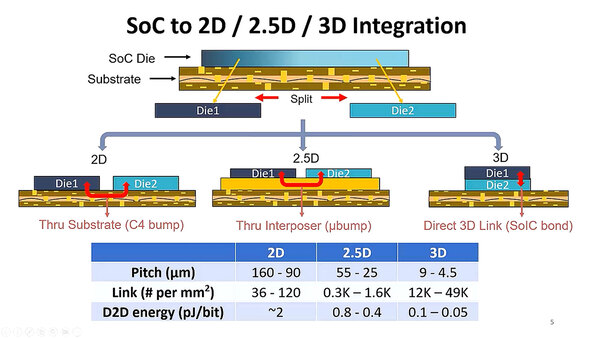
左はパッケージに直接搭載する方法。RyzenやEPYCだ。中央がシリコンインターポーザー、そして右がSoICである
TSMCの場合、CoWoS、InFo、SoICという3種類のチップレット接続のテクノロジーを提供しているが、ここのテーマは次世代のSoICである。2nmプロセスの説明のスライドの中にもこれに言及したものがあるが、次世代のSoICではおおむね2倍の帯域をほぼ同等の電力で利用できるようになるとする。
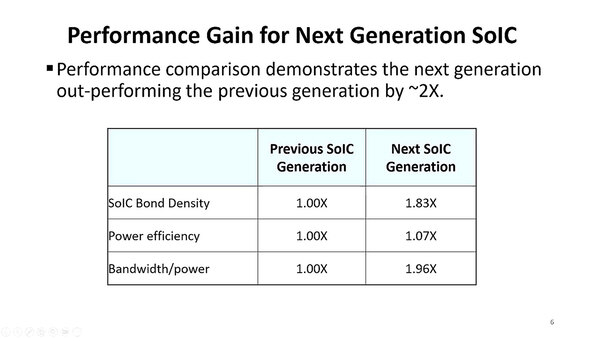
9μm→4.5μmでは密度は4倍になりそうなものだが、1.83倍ということは9μm→6.65μmなのか、それとも6.09μm→4.5μmなのか、あるいは縦方向と横方向でピッチの縮小具合が異なるのか、いろいろ謎である
実際にTSMCのN3でテストチップを製造する際の工程が下の画像である。当然であるが、SoICを構築する際には接続面のPlanarization(平面化)の工程が必要であり、これには後工程の平坦化レベルでは足りず、前工程の装置を利用しての平坦化が必要となる事を示している。OSAT(後工程を担当する企業)のソリューションに、こうした3D積層が出てこない理由の1つがこれである。
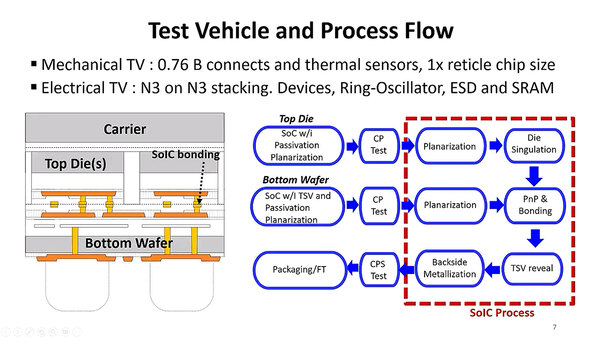
ずいぶんTSVの数が多い(7億6000万個)とは思うが、テストチップの大きさは25×33.3mmとかなり大きなものなので、9μmピッチで製造したとしてもはるかに多数のTSVを積層可能である。テスト用だからこのくらいの数があっても不思議ではない
上の画像の右中央にあるのがPnP & Bondingである。PnPはPick & Placeの略で、2枚の向かい合わせになったダイの位置を合わせて結合するというステップであるが、この際に正しく位置合わせをして接続できているかを確認するための検査手段がCSAM(Confocal Scanning Acoustic Microscopy)である。
超音波顕微鏡の一種であるが、2次元走査を行なうことが特徴である。破壊検査はしようがないので、超音波顕微鏡を使って正しく重なり合っていることを確認するというものだ。ちなみに上の画像では、ダイ同士の接続というよりはWoW(Wafar on Wafer)の形で2種類のダイ(を搭載したウェハー)を重ね、後で切り出すような構造に見えなくもない。
上の画像ではSoICプロセスに入る前にCPテスト(Chip Probing、あるいはCircuit Probingの意味だが、おそらく前者だろう)を行なっているので、ダイシング(ウェハーからダイを切り出す)を実行した後かと思ったのだが、CPテストはダイシング前に行なうことも不可能ではないので、WoWの場合には切り出さずにそのままSoICプロセスをかける形になるのかもしれない。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ













で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")













































