



ロードマップでわかる!当世プロセッサー事情 第783回
Lunar LakeにはWi-Fi 7があるがPCIe x16レーンは存在しない インテル CPUロードマップ
2024年08月05日 12時00分更新

前回まででLunar Lakeのコンピュート・タイルの話は完了である。ということで残りはプラットフォーム・コントローラー・タイルの話である。
Intel Thread Directorを改良
まずEコアで実行し一定以上の負荷であればPコアに移行する
なぜプラットフォーム・コントローラー・タイルで真っ先にThread Directorが出てくるか? というと、パワーマネジメント関係の制御が搭載されているためである。
さて、Meteor LakeではThread Directorにずいぶん手が入ったという話は連載739回で説明した。Meteor LakeではSoCタイルにLow PowerのEコアが搭載されている関係で、まずはこのEコアで動かした上で、必要に応じてコンピュート・タイルのEコアや、それ経由でPコアに移行するという仕組みであったが、Lunar LakeではこのLow Power Eコアが存在しない関係で、またAlder Lake/Raptor Lakeに近い方法に戻ったのだが、実装が逆になった。
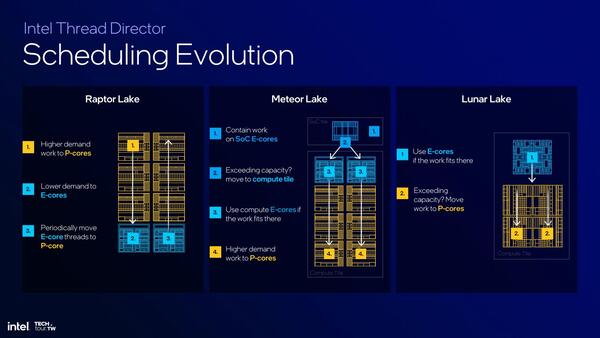
Meteor LakeではPコアの前にコンピュート・タイル上のEコアが先に使われるが、これはおそらくSoCタイルのLow Power Eコアからの処理の移行が容易なためだろう
つまりAlder Lake/Raptor LakeではまずPコアで処理を行ない、ここで負荷がしきい値以下であればEコアに移行させるという方式だったのに対し、Lunar LakeではまずEコアで実行し、ここでしきい値以上の負荷であればPコアに移行する仕組みになっている。
正直この仕組みが一番シンプルでいいとは思うのだが、Alder Lake/Raptor Lake世代でまずPコアに処理が割り振られたのは、当時のEコアでは性能が低すぎてすぐにEコア→Pコアの移行が入ってむしろオーバーヘッドが大きくなってしまうためだと考えられる。
ところがLunar Lake世代ではEコアの性能が大幅に上がったことで、おそらくはAlder Lake/Raptor Lakeとは逆に、まずEコアで動かした方が移行のオーバーヘッドが少ない(まずPコアで動かすと、むしろPコア→Eコアの移行が多くなりすぎる)ものと考えられる。
実際にLunar Lakeで負荷の高い処理(ここではOffice Productivity)を実行した様子が下の画像だ。まず最初にEコアで処理をスタートし、すぐにEコアからPコアに処理が移行しているのがわかる。

Meteor Lakeでかなり難しくなっていたThread Directorの動き方がだいぶシンプルになった感はある。ただArrow Lake世代でどうなるのかはまだわからない
ちなみにこの基本的なスケジューリング方法の違いとは別に4項目の改良が成されたとしている。

"Innovations"とは言っても、新機能というよりは従来からの改善であり、これによって「どの程度改善したか」の数値は示されていないのが残念である
1つ目の"Optimize right workload for right core"に関する説明が下の画像であるが、今ひとつ具体的になにをどうした? という話は不明ではある。

この話は次の"OS containment zone"にも絡んでくる。ちなみに"for experience continuity"というのは別にハードウェア側の話ではなく、Thread Director用の管理ソフト(というよりドライバー)の話な気がする
ただこれまでよりもスレッドの負荷を細かく監視するほか、OSへのHint(スケジューラに対するスレッド負荷に関する情報)の出し方に、低電力/低発熱の部分を加味したことが示されている。
2つ目の"Tighter OS integration"は、以前から事前にわかるものに関しては"Efficient Zone"/"Hybrid/Compute Zone"にあらかじめ登録しておき、Thread Directorで素早くそのスレッドを目的のコアに割り振る一方、そうした登録に入っていない"Zoneless"に関しては引き続き従来の方法(つまりまずEコアで動かし、そこで負荷が高いようならPコアに移行する)を利用する格好になるようだ。
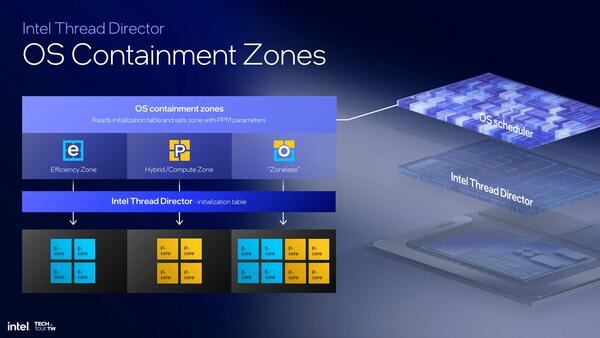
もっとも、例えばOfficeのワークロードも、PCMark 10やProcyonで使った場合と人間が使った場合では負荷状況が違う気がするので、これをThread DirectorはZoneに入れるのか、Zonelessで扱うのか、などいろいろ疑問は尽きない
おそらくはThread Directorで負荷状況を監視する中で、後追いでどちらのZoneにすべきか、あるいはZonelessで扱うべきかを判断してリストに入れる(これはThread Directorのドライバーの仕事だろう)ような処理が行なわれているものと思われる。下の画像にあるマイクロソフトのコメントもそれを裏付けているように思われる。

Teamsを使う時にはおそらく無条件でEコアを使うように設定してくれるので、Lunar Lakeではより長時間の利用が可能になるという話で、このあたりはOS側でThread Director経由で稼働データを収集し、これに応じてContainment Zoneの情報をアップデートしているように読める
3つ目の"Enhance capabilities for efficiency"は、電力管理のモードにあわせてThread Directorの振る舞いを変更するという話である。
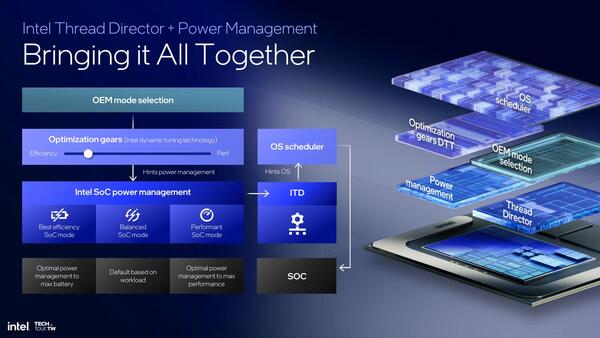
電力管理のモードにあわせてThread Directorの振る舞いを変する。これに関しては「まだ実装されてなかったのか?」という驚きの方が多いのだが、実は実装されていて、ただそれがさらに改良されたという話なのかもしれない。ちなみにITDは"Intel Thread Director"のことである
例えばACモードとバッテリーパワーモードでは、EコアからPコアに移行するための処理負荷のしきい値が変わり、よりEコアを利用するようになる、といった設定のされ方が考えられる。
ただ以前インテルは「長時間低消費電力のコアを動かすより、短時間高性能コアを動かした方がトータルでの消費電力が減る」といった見解を出していた時期もあったりしたので、これは要するにEコアの性能が大幅に上がり、同じ処理をするならEコアを使った方がトータルでの消費電力量(消費電力×経過時間)が減り、結局バッテリー寿命の延伸に貢献できるという目途が立ったから実装した、という可能性もある。
実際の数字では、同じLunar Lake上であってもContainmentとPower Managementを両方有効にすることで、35%の消費電力削減が可能になった、としている。

ContainmentとPower Managementを両方有効にすることで、35%の消費電力削減が可能。アプリケーションからContainment Zoneを無効にする方法があるということだろうか?
最後の"Consuming platform intent"は主にアプリケーション開発者向けの話であって、ハードウェア依存度を高めるのではなくQoS APIを使おうと呼びかけているわけだが、インテルだけならともかくAMDのプラットフォームもあることを考えると、これは無駄にアプリケーション開発者の負荷を高める方向に行くような気もしなくはない。ただ例えばAI PC向けのAIベースアプリケーションであれば過去への互換性はある程度無視できるので、意味があるのかもしれないが。

"Latest ISA"と言われても、AVX512を使ったらそもそもLunar Lakeは動かないし、Lunar Lakeでしか動かない命令(これはいくつかある)では他のプラットフォームとの互換性が保てないため、結局プログラムの冒頭でアーキテクチャーを判断して処理を分岐することにならざるを得ないわけで、言うほどに簡単ではない
ちなみに今後の方向性として示されたのが下の画像だ。"Increasing scenario granularity"はわかるし、"AI-based scheduling hints"も、実装をどうするのかやや疑問ではあるが、方向性としてはわからなくもない。

"AI-based scheduling"といっても、なにをAIでやるか次第(スケジュール全部をやるわけではないだろう)なので、実装できなくはない
謎なのが"Cross IP scheduling"で、これは単にCPU(Pコア/Eコア)だけでなくNPUやGPUまで含めたスケジュールを意味しているらしいのだが、もう少し解説が欲しいところだ(説明では軽く"CPUだけでなくNPUなんかも"で流されてしまった)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























