




ライティングと発色は美しい。リアル系の画像は写真レベル
実際に出力はどうか。
サンプルとして公開されているワークフローで生成してみるとかなりきれいに出ました。SD3Mでは自然なライティングができていたりと、SDXLより優れていると感じられる部分はあります。SDXLで同じような発色を出そうと思うと、ファインチューニング(微調整)したカスタムモデルや、LoRAを組み合わせなければ難しいのではないかと思います。ただ、劇的に変化したかというと、そこまでは達していないように感じます。

SD3Mでサンプルのワークフローで生成した画像。ライティングの雰囲気は今までにない可能性を感じる
サンプルのワークフローでは、画像は1024×1024というSDXLと同様の解像度で出力されます。ディティールを書き出してもくれるので少し物足りなくも感じますが、画像はディティールや画質を維持したまま画像サイズを拡大できるアップスケーラーを使うのが前提になっているようです。こちらもサンプルのワークフローが用意されています。
テストのため、自然文での長文プロンプトを簡単に生成するのにいい方法がないかと考えたのですが、ChatGPTに自分のプロフィール写真を解析させる方法を取りました。日本人の中年男性を描写するプロンプトが生成されました。それでSD3Mで生成してみたところ、どこかにいそうな妙な実在感のある中年男性が出てきました(笑)。プロフィール写真としてはそのまま使えそうなリアルさで、一見写真と見間違えてしまいそうです。写真っぽい印象は非常に自然で、単純な生成だけで、ここまで出せるというのはすごいとは思います。

SD3Mの人物描写は強い。どこかにいそうな中年男性が生成された(筆者の写真をChatGPTにプロンプト化させたものを使っており、画像を参照として使っていないので似てはいない)
複雑な場面もテキストだけで生成可能。ただし気になる部分も
次に、サンプルワークフローで公開されている「マルチCLIP」という機能を使い、複雑なプロンプトを試してみます。
これは3種類のプロンプトを同時に入力し、それぞれのプロンプトを公平に反映させるという、MMDiTの強さを生かした仕組みです。これまではタグごとに分けた形で入力するのが基本で、プロンプトの影響力は前に書かれている単語ほど影響力が大きいものでした。一方、SD3Mでは、3種類の分割したプロンプトに同じ重みで生成ができるようになっています。
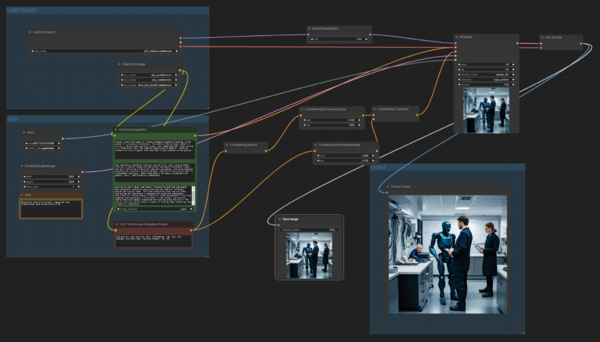
マルチクリップのサンプルワークフロー。グリーンの部分に、3つのテキストボックスがあり、そこに別々の文章を入力する
試しに「アンドロイドがいる研究室」という条件で、やはり同じようにChatGPTでプロンプトを作成してみました。
その複雑なプロンプトを3つに分割して、CLIPの1つ目に「アンドロイド」、2つ目に「研究室」、3つ目に「背景」の詳細をそれぞれ入れて生成してみました。生成された画像を見てみると、細かいところの破綻はありますが、研究室のホワイトボードに数式やグラフらしきものが書いてあったり、ディテールがちゃんと出ています。さらに、プロンプトの要素の一部だけを修正して構成要素を変えたりできるようにもなっています。

研究室をテーマに生成した3枚
これがSD3ならではの特徴です。複雑なプロンプトにより、複雑な場面を生み出せるわけです。
ただし、気になる部分もありました。女性アンドロイドを指定して何度か生成してみたのですが、なんとなくプロンプトが無視されている気がします。プロンプトが長すぎるのかもしれません。ただ、DALL·E 3(ChatGPT)で画像を同じプロンプトで生成した場合には、きちんと女性アンドロイドが出ています。プロンプトをシンプルにするとSD3Mでも出力できたので、効果が大きいテキストの量は存在しそうです。

研究室にいる女性アンドロイドについての複雑なプロンプトをDALL·E 3で生成したもの(左)。SD3Mでプロンプトを女性アンドロイドのみに絞り込んで生成したもの(右)
アニメ系は基本的にはそれなりにきれいな描画が出るものの、指や髪の破綻が激しいですね。この辺りはSDXLの基本的な特徴を引き継いでいるような印象も受けます。

SD3Mで、「日本のアニメ少女」と指定して生成
参考までに、昨年の記事で作成した画像を同じようにChatGPTに解析させて、同じように長文プロンプトを作成し、それらにどれぐらい近い画像を生成できるのかを、様々なサービスで比較してみました。SD3M、DALL·E 3(ChatGPT)、Midjouney、Nijijounery、NovelAIの各種です。ポイントは色の違いで、赤、青、緑・黄というキャラクターの服装の違いを描画できるかというところですが、SD3Mでもそれなりにできてはいるようです。ただ、やや棒立ちに近く、そのままでは魅力的な画像とは言えませんでした。とはいえ、今後ファインチューニングがされれば、かなり改善してくる可能性が感じられます。

SD3Mで生成した3人のキャラクター。3人のキャラクターの特徴付けは一応できている

同じプロンプトでのDALL·E 3(左上)、Midjouney(右上)、Nijijounery(左下)、Novel AI(右下)。絵としての魅力単体では、Nijijouneryがかなり勝っている。Novel AIはSDXLベースと言われているため、長文のプロンプトの認識力に難がある
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















