



ロードマップでわかる!当世プロセッサー事情 第716回
Radeon Pro W7900/W7800が異様に安い価格で投入される理由 AMD GPUロードマップ
2023年04月24日 12時00分更新

4月14日、AMDはRadeon Pro W7900とRadeon Pro W7800の2製品を発表した。内容は発表記事にあるとおりで、基本Navi 31ベース、つまりRadeon RX 7900 XT/XTXをベースにしながら、多少動作プロファイルを変更し、かつRadeon Pro Driverでの検証を行なった「だけ」で、あまり新しい話はない。

AMDがRadeon Pro W7900とRadeon Pro W7800を発表
もっとも発表資料を仔細に見るといろいろ突っ込みどころはあり、中の人も苦労したんだなぁというのが良くわかるが、それは後で説明するとして、まず触れたいのはRadeon Pro W7800の方である。
Radeon Pro W7800の性能は
GeForce RTX 4070 Tiと同程度か少し上
| Radeon Pro W7900とW7800のスペック | ||||||
|---|---|---|---|---|---|---|
| Radeon Pro W7900 | Radeon Pro W7800 | Radeon RX 7900XTX | Radeon RX 7900XT | |||
| Shader Engine数 | 6 | 5(推定) | 6 | 6 | ||
| CU数 | 96 | 70 | 96 | 84 | ||
| SP数 | 6144 | 4480 | 6144 | 5376 | ||
| MCD数 | 6 | 4 | 6 | 5 | ||
| InfinityCache | 96MB | 64MB | 96MB | 80MB | ||
| MemoryBus | 384bit | 256bit | 384bit | 320bit | ||
| Peak FP32性能 | 61.3TFlops | 45.2TFlops | 61.3TFlops | 52TFlops | ||
| Boost周波数 | 2.5GHz(推定) | 2.5GHz(推定) | 2.5GHz | 2.4GHz | ||
| TGP/TBP | 295W | 260W | 355W | 315W | ||
上表がRadeon Pro W7900とW7800のスペック一覧である。W7900の方はほぼNavi 31のフルスペックと考えて良い。ほぼRadeon RX 7900XTXをそのまま、といったところだ。Boost周波数は、Peak FP32の性能が同じ61.3TFlopsになっていることから、こちらは2.5GHzのままと考えられる。
ただRadeon RX 7900XTXのTBP(Typical Board Power)は355Wなのに対し、Radeon Pro W7900のTGP(Typical Graphics Power)が295Wなのは、Power Profileを操作してTypicalで295Wに収まるように調整しているものと考えられる。
実際Radeon RX 7900XTXの場合、標準でPower Limitは-10%~+15%で、つまりTBPは319.5~408.3Wほどの範囲になっている。ただここでPower Limitを-17%程度まで拡大すれば295Wに収まる計算だ。ワークステーション用途が主とは言え、場合によっては3U程度のシャーシに収めてラックに格納、ということも考えられるから、300Wの枠は守りたかったものと思われる。
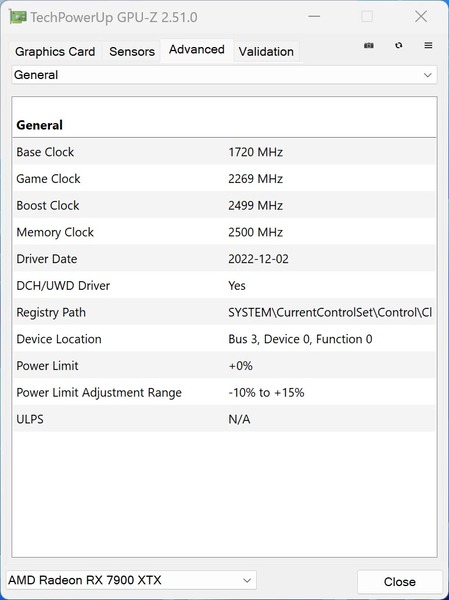
Radeon RX 7900 XTXのFirmware Settingの内容をGPU-Zで示したもの。もう少しPower Limitの下限を下げてくれてもかまわないと思うのだが
次にW7800の動作周波数だが、ピークのFP32の演算性能が45.2TFlopsと説明されており、W7900とのCU数の比からこちらもほぼ2.5GHzのままと想像される。それでもCU数が大幅に減っている分、消費電力はCU数に比例して下がることが期待される。
CU数の比で計算すると、Radeon Pro W7800のTGPは215Wまで下がる計算であり、実際は260Wと比較的余裕があることを考えると、Power ProfileそのものはRadeon Pro W7800の方がやや高めに設定されているものと考えられる。
ところで構成であるが、非常におもしろい。もともとNavi 31は6つのShader Engineを搭載しており、各々のShader Engineに16個づつのCUが搭載されるという構図だった。
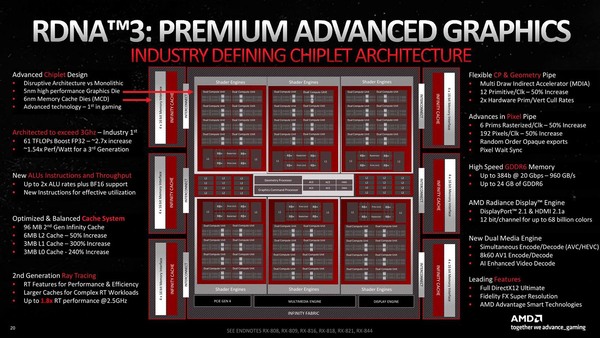
Navi 31の構造。各Shader Engineに16個のCUが搭載される
ではRadeon Pro W7800は? というと70CUになるので、必要となるShader Engineの数は70÷16=4.375で、4つでは足りず5つ必要とになる。
6つのままという可能性もあるが、70で割り切るのは面倒(72CUなどだったらあり得たかもしれない)だし、Shader Engineをまるまる1個無効化できるから、歩留まり向上の意味でも効果的ではあるとは思う。かつ、5つのShader Engineの16CUのうち2CUを無効化し、14CU×5=70CUという構成にしている。図にすると下のようになる。

左がフルセットのNavi31、右がRadeon Pro W7800で利用されたものの想像となる
この構成がおもしろいと思うのは、MCDは4つしかないことだ。メモリーバスはMCDあたり64bitなので、256bitメモリーということはMCDは4つという計算になる。またインフィニティ・キャッシュの容量も64MBとされており、ここからもMCDは4つとはっきりわかる。
なにがおもしろいかというと、このバランスで性能が出ていることだ。最初筆者はMCDは5つで、ただしそのうちGDDR6を接続しない形で、単にインフィニティ・キャッシュだけを使っているのかと思った。実際Shader Engineが6つにMCDが6つでバランスしてるなら、Shader Engineが5つならばMCDも5つ必要だと考えるのは普通だろう。ところが実際には4つでバランスする、というのは意外にインフィニティ・キャッシュの効率が良いということになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























