ロードマップでわかる!当世プロセッサー事情 第701回
性能が8倍に向上したデータセンター向けAPU「Instinct MI300」 AMD CPUロードマップ
2023年01月09日 12時00分更新


5nmチップレットが9個、6nmチップレットが4つとのことだが……
さて、ここからもう少し深く見ていきたい。まずSu CEOの説明によれば5nmチップレットが9個、6nmチップレットが4つなのだが、まずこの数が上の画像と全然合っていない。
下の画像はスライドからパッケージ部を大きく引き伸ばした上で試しにレイアウトを分類してみた構図だ。
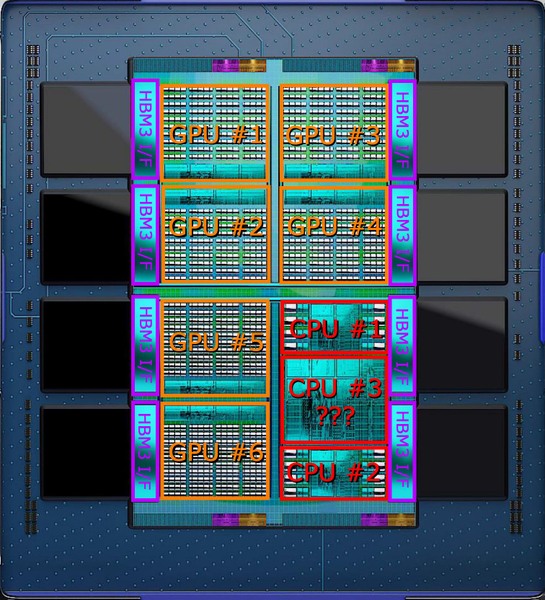
Instinct MI300の構造。区分けはしていないが、上下に配されている部分はPCIeと共用のインフィニティ・ファブリックのI/Fと思われる。これは外部接続用に用意されているものと考えられる
構造としては、上層にCPUチップレット×3とGPUチップレット×6があり、これはいずれも5nmで製造される。その一方で、下層には6nmで製造されたチップレット×4が配される。このチップレットはHBM3のI/F×2と、インフィニティ・ファブリックのI/F、それとおそらくは大容量の3次キャッシュを持つ形になる。この下層の6nmのチップレットの想像図が下の画像だ。
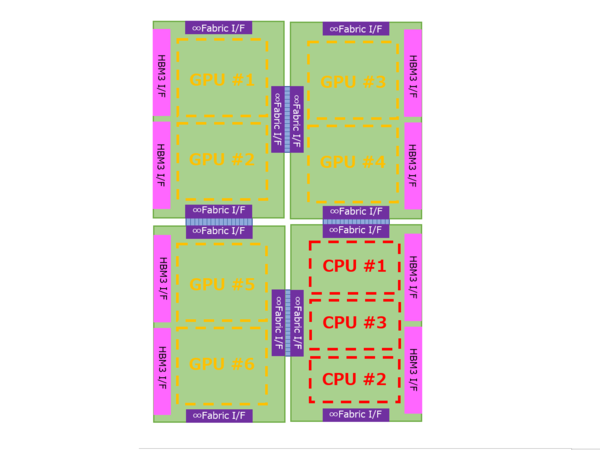
6nmのチップレットの想像図
この4つのチップレットが厳密な意味で同じか? というと少し怪しい。構図で言えば、Sapphire Rapidsの4つのタイルをどう作るかという話と同じである。
上図で言えば、右下と左上、右上と左下はそれぞれ同じにできる「可能性がある」。ただ4つのタイルを完全に同じにするのは難しいだろう。それともう1つ、右下と左上のタイルは同一にできるか? というと不可能ではないが難しいだろう。
左上はCDNA 3のタイルが2つ載り、右下はZen 4のタイルが3つ載る。これを同一のタイルで実装するのはけっこう至難の業である。普通に考えたら別々にするのが妥当だろう。
そして、性能を上げるためには大容量キャッシュはどうしても必要になる。HBM3は合計の帯域は凄まじいが、GPUタイルあたり1つ、CPUに至っては3タイルで2つなので、実はCPU/GPUの演算ユニットあたりの帯域で考えるとそれほど大きいものではない。
加えて言えば、HBMはメモリーアクセスのレイテンシーが大きい。同様に大量のHBM2eを集積するPonte VecchioはRAMBOキャッシュを別タイルの形で実装しているし、Instinct MI250Xにしてもタイルあたり8MBの2次キャッシュを搭載している。
これはMI300も同じで、CUの塊とは別に大きなブロックがある。おそらく5nmのタイルの方に2次キャシュを搭載しており、それとは別に3次キャッシュを6nmのタイルの方に実装している、と筆者は考えている。
ちなみにGraphCoreのBOWや、Meteor Lakeのように、この下側のタイルがパワーデリバリー用という可能性も皆無ではないが、実際には違うと考えている。それはプロセスに起因する。
GraphCoreのBOWは公開されていない(TSMCの40nmという説もあるが、公式発表はない)が、Meteor LakeはIntel 22FFLである。連載658回でも説明したが、そもそもパワーデリバリー用であればTSMC N6である必要はまったくなく、もっと安価な28nmや40nmなどでも十分お釣りがくる。
もちろんHBMのI/Fとインフィニティ・ファブリックのI/Fが必要なので、そのあたりを勘案するとN6の方が都合が良いのはわかるが、N6のウェハーを使ってパワーデリバリーというのは、あまりにコスト的に無駄がありすぎる。
それに、もしパワーデリバリーが本当に必要なら、N5タイルとN6タイルの下に、さらにパワーデリバリー用の階層を設けることも不可能ではない。逆に言えば、N6タイルはそれ以外の用途に使うと考えた方がいいだろう。そしてN6は大容量のキャッシュの構成に都合がいい、という話はRadeon RX 7900シリーズの説明で述べたとおりだ。
さて、GPUの方はこれでいいとして、問題はCPUの方だ。MI300は24コアのZen 4コアを搭載する。ということは普通に考えれば8コアのタイル×3だ。実際下の画像を見ると、CPU #1とCPU #2は普通の8コアタイルだ。
Instinct MI300の構造
寸法から言って、Ryzen 7000シリーズやEPYC 9004シリーズのCCDとは異なる(3次キャッシュがやや大きめ?)ように見えるが、そもそもRyzen 7000シリーズやEPYC 9004シリーズのCCDがそのまま使えるとは限らない。こちらは普通のオーガニックパッケージにC4 Bumpの形で実装される。一方Instinct MI300は3D積層なので、SoICに向けた構造が必要になる。
それはともかくとして#1と#2はまだ理解できる。理解できないのが倍近くのサイズのCPU #3である。構造的にはこれがキャッシュにしか見えないのだが、するとCPUコアの数が足りない。
そもそも上の画像のCGが本当に正確なのか? というあたりから疑わないといけなくなっているのだが、今回実物が示されたものの、CGと一緒かどうかを判断するにはやや解像度が足りない。ということで、この件はもう少し詳細がわかるまで先送りとさせていただきたい。

Instinct MI300の実物。なにしろ1080Pの動画なので、これ以上詳細な映像がない

映像を拡大したものの、HBM3は見分けがつくがCPUやGPUのタイルの区別はつかない
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













