




連載622回でGraphcoreのIPUを紹介した。そのGraphcoreが、今年3月3日に第3世代のIPUであるBOWを発表した。
このBOW、TSMCのSoIC-WoWを使って製造されたチップとなっている。ただSoICの使い方があまりに斬新すぎるので、今回はこのBOWを紹介したい。
IPU Mk2から40%性能が向上し
価格はIPU Mk2と同じという「BOW」
そもそもBOWの名前の由来について一切説明がない(まさかRed君の鳴き声というわけでもないと思うのだが……)のだが、そのBOW IPUの概略が下の画像だ。

BOW IPUの概略。パッケージそのものは基本変わらず。以前の第2世代IPUのシリアルが“115-0084 T6N390.00”、BOWが“115-0804 N9T238.00”というあたりでしか見分けがつかない
IPU Mk2とスペックを比較してみると、とりあえず“3D Silicon wafer stacked processor”を置いておくとして、以下のようになっており、ハードウェア的には基本一緒である。
| IPU Mk2とBOW IPUの比較 | ||||||
|---|---|---|---|---|---|---|
| 性能 | 250TFlops→350TFlops | |||||
| メモリー容量 | 900MB→0.9GB(要するに変わらず) | |||||
| メモリー帯域 | 47.5TB/秒→65TB/秒 | |||||
| IPU Core数 | 1472→1472(変わらず) | |||||
| プログラム実行数 | 8832→8832(変わらず) | |||||
| IPU Links | 10x 320GB/秒→10x 320GB/秒(変わらず) | |||||
では性能やメモリー帯域の違いは? という話だが、動作周波数が1.35GHz→1.85GHzと37%ほど向上しており、これが性能向上(40%)やメモリー帯域向上(36.8%)につながった。
この結果として、主要なアプリケーションについて、軒並み30%台の向上が得られたというのが同社の説明である。
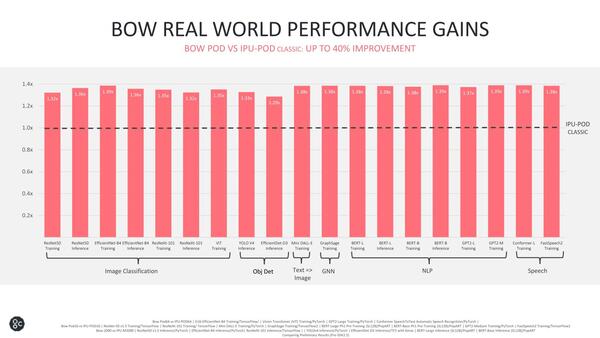
動作周波数が上がり、これにともない内部SRAMへのアクセス速度も上がっているから、性能向上は当然の結果である
IPU Mk2(グラフではIPU-POD Classicと表現されている)とNVIDIA DGX A100の比較結果は連載622回で紹介した通りで、例えばRESNET-50の学習時間を比較するとDGX A100が28.77分、対してIPU-POD16では37.12分だったのが、これが1.32倍高速になって28.12分程度にまで高速化される計算になり、DGX A100と同程度のピーク性能でありながら、価格は半額のまま据え置きで、性能/価格比は2倍まで向上、というのが同社の説明である。ちなみにBOW IPUは価格がIPU Mk2とまったく一緒である、とされている。
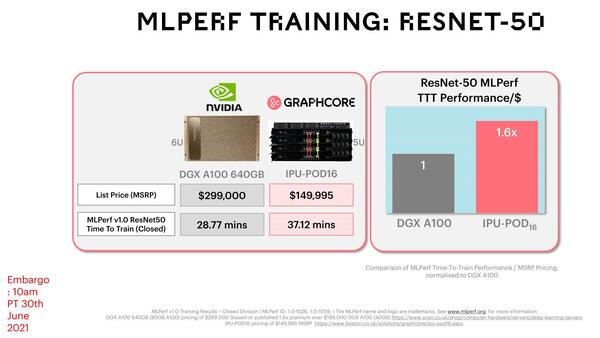
IPU Mk2とNVIDIA DGX A100の比較結果
ところでどうやって性能を向上させているか? であるが、構造を変えずにIPUを作り替えた(例えばTSMC N6に移行した)という話か? と思ったら、“BOWのダイは、IPU Mk2とまったく一緒(exact same)だ”という説明があった。
それでは3D Stackingはどこに出てくるのだ? となるわけである。通常3D Stackingと言えば、ロジックプロセスないしSRAMを積層するという話が思いつく。ただIPUの数は同じなのでロジックの積層はあり得ないし、SRAMを積層すればメモリーが増えるわけで、これもない。これに関しての同社の説明が下の画像だ。
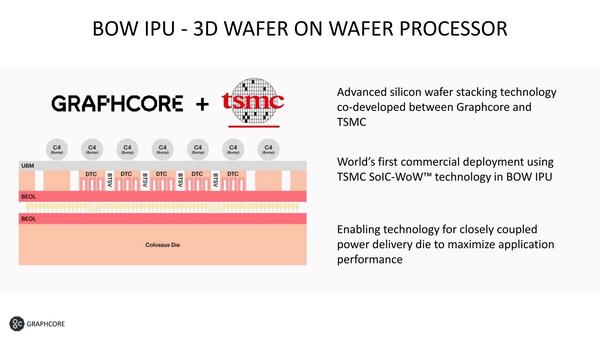
BOW模式図。BSTVは信号配線に使われる
この図では上下がひっくり返しになっているが、要するにIPU Mk2のダイをそのままに、従来だったらC4 Bumpの形でBallが出ていたところを一度取り去り、そこにウェハーを挟んで、その上にC4 Bumpを改めて構成した格好だ。
間に挟まっているウェハーであるが、その中身はBTSV(Back-side Thought Silicon VIA)とDTC(Deep Trench Capacitor)である。BTSVは、IPU Mk2から出た信号をC4 Bumpまで伝えるのが仕事である。DTCは、シリコンに溝を掘りそこをコンデンサーとして使う技法で、eDRAM(Embedded DRAM)などでも利用されているものである。現在のDRAMはDTCで構成されているので、その意味ではDRAMそのものと誤解しそうである。
これを見て「トップウェハーにeDRAMを積層したという理解でいいのか?」といった質問が殺到したが、答えはNo。なんと同社はこのDTCを、パスコン(バイパスコンデンサー)として使うという、前代未聞の実装を披露してくれた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












