ロードマップでわかる!当世プロセッサー事情 第689回
Zen 4アーキテクチャー詳細の続報 3D V-Cacheやメモリー、内蔵GPUなど AMD CPUロードマップ
2022年10月17日 12時00分更新

連載687回でZen 4の内部構造を解説したが、そこで書ききれなかった話を今回まとめて説明しよう。

3D V-Cacheのダイ構造がようやく判明
Zen 4世代でも同じく64MBダイを1個搭載する?
Zen 4のアップデートと銘打っておいていきなりZen 3世代に話が戻るのだが、Zen 4でも3D V-Cache搭載製品が登場する予定になっている。その絡みで3D V-Cacheの物理構造が判明したので説明したい。
3D V-Cacheの最初の内部構造は連載618回で説明したとおり。ついでTech InsightによるTSV周りの解析結果を連載651回で説明した。そして今年のISSCCでAMDが公開した3D V-Cache周りの説明が連載659回である。
これで電気的な接続方法や物理的な構造などはほぼすべて明らかにされた格好だが、唯一不明だったのがダイそのものの容量にまつわる謎である。
もともとZen 3ではCCD上の3次キャッシュの面積はほぼ36mm2ほど。そして3D V-Cacheもやはりダイ1つあたり36mm2ほどになっており、普通に考えたらダイ1つの容量は32MBにならないとおかしいのだが、AMDは一貫して「ダイ1つで64MB」と説明している。この謎を解くにはやはり直接スタッフに聞かないとどうしようもないのだが、やっと今回Zen 4にかこつけてこうした機会に恵まれたわけだ。
さて筆者はこのミスマッチに関し「32MB 3D V-Cacheのダイを2枚積層しており、AMDはこの2枚を1つのダイと称しているのではないか?」とこれまで説明してきたのだが、これは半分正解、半分間違いであった。
スタッフの説明による3D V-Cacheの製造方法が下図に示す形だ。
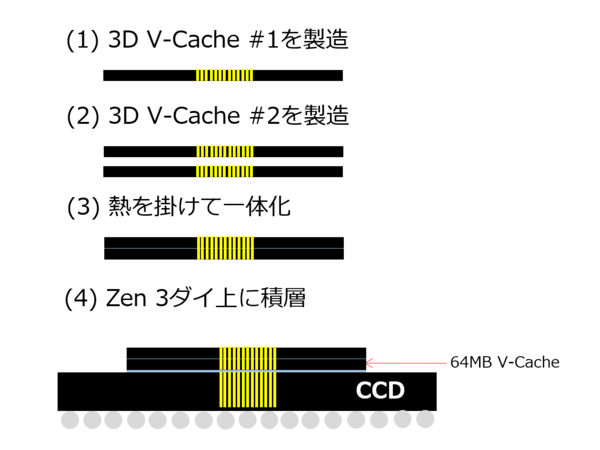
3D V-Cacheの製造方法
まず32MBのSRAMダイを2つ製造する((1)と(2))。このSRAMダイは、複雑な配線層は要らない(SRAMのルーティングはTSVを経由してCCD側で行なう)から、SRAMそのものを構成するのに必要なM1~M2(M3?)+2層程度で製造可能だろう。
ただしCCDと異なり、積層する関係でシリコンそのものは限界まで削る(多分絶縁用のSiO2層を残す程度)必要があるので、CCDよりは製造工程は減る一方で、CCDとは異なる工程が入る格好になる。
こうして2枚の32MB SRAMができたら、これに熱をかけて一体化させる(3)。これによって、AMDのいう「1枚で64MBのSRAMダイ」ができあがる格好だ。最後にこれをCCDに積層(4)して、作業は終了である。なるほど、AMDが「1ダイあたり64MB」と説明するわけである。
なぜこんな構造にしたのか? 逆に言えば、SoICを使って2層を積層する方策を取らなかった理由はなぜか? という話に関しては今回も不明なままである。
ただ可能性で言えば、今でこそSoICはある程度実績も増えてきたが、AMDがZen 3の設計をしていた当時はそこまでの信頼性を確保しきれていなかった、というあたりが正確なところなのかもしれない。
ダイをTSV経由で3D積層することそのものが当時はチャレンジであり、積層するダイを2枚にするのはさらに難易度が上がる、という判断だったとしても不思議ではない。
逆に言えば、Zen 4世代でも同じように1つのダイに集積した上で実装するのか、それとも32MBのダイを2枚積層する形にするのかは、まだ定かではない。ただAMDのこれまでの流れで考えると、自身で開発した新技術をけっこう大事に長期間使う傾向があることを考えると、Zen 4世代でも同じく64MBダイを1個搭載する形になるように思える。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













