
メモリーアクセスの頻度によって性能が変わる
一連のANSYS Fluentの結果でわかるのは、「なんでも一律に性能が上がるわけではない」ということだ。要するにL3を96MBまで増量した結果、メモリーアクセスが多く発生するケースでL3 Hitの確率が増え、その分メモリーアクセスが削減でき、性能が上がるという仕組みであるのだが、以下のように、見かけ上性能向上がそれほど大きくないケースもある。
- メモリーアクセスが少ない=Milanの32MB L3でもそこそこHitする→性能改善の効果が薄い(例えば2M個の要素を持つ飛行機のaircraft_2mの場合)
- メモリアクセスが多すぎる=Milan-Xの96MB L3でもあふれてしまう→性能改善の効果が薄い(例えばF1のレーシングカーのモデリングやガスタービンの燃焼器の128VMの場合)
その一方で、96MB L3がうまくサイズ的にマッチするケース(例えばF1のレーシングカーのモデリングの64VM)では大きな性能向上が期待できるわけで、このあたりは実施するアプリケーションがどの程度メモリーアクセスを行なうかにかかっている。
下の画像はOpenFOAM v.1912の例だが、やはり1VMだとMilanでもそこそこL3が足りているようで性能向上はそう大きくないし、32VMでは逆にMilan-XでもL3が足りなくなるようで、結果として性能向上が大きくないが、8VMあたりだと大きく性能を向上させているあたりは、やはりデータ量とのバランスに依存することになる。
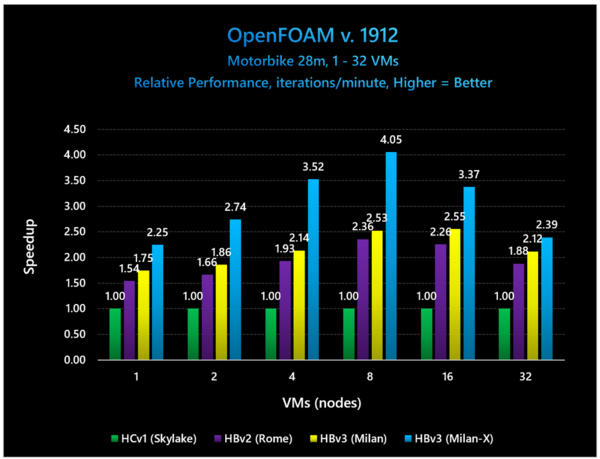
OpenFOAMもやはり流体解析のソフトである。これは28M要素のオートバイの解析のケースである
とはいえ、32VMの場合でも12%程の性能向上が余分な消費電力増がほとんどなしに実現できているあたりは、やはりL3増量の効果は大きいというべきか。
次の画像はSiemensのSimcenter Star-CCM+での結果である。こちらではあまり顕著な差がないというか、じわじわ差が広がっていく感じになっているが、1VMではMilan比で7%ほどの改善でしかないのが、128VMでは18.5%まで差が広がるあたりは、ワークロードが重いケースでの性能改善が著しいということになる。
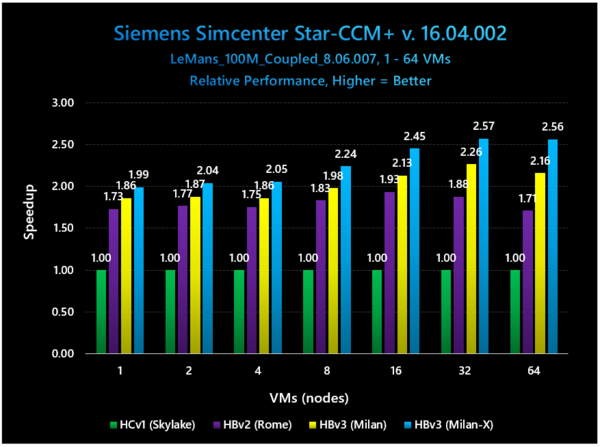
Simcenter STAR-CCM+もまた、流体解析のソフトである。今回は要素数100Mのル・マン出場車(やはりレーシングカー)での例である
次はWRF(The Weather Research & Forcasting model)という気象予測モデルのシミュレーションを使い、2.5Kmグリッドで予測した際の性能である。
こちらはMilan vs Milan-Xというわかりやすい構図であるが、やはり8VMあたりが一番性能が高く24%の向上。1VMでは8%でしかないが、64VMでも14%ほど向上するあたりは、ワークロードが高くてL3が溢れるようなケースでも、一定の性能向上が得られることを示している。
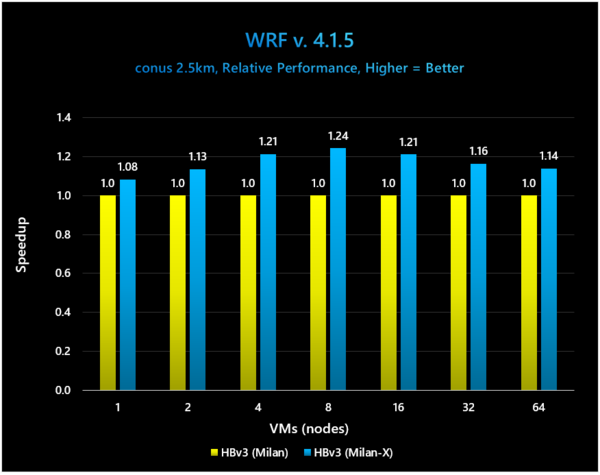
WRFはNCAR(National Center for Atmospheric Research:アメリカ大気研究センター)が提供する気象予測のシミュレーション用モデルである。現時点での最新版はV4.2.2なので、やや古い結果である
最後がNAMDという分子動力学シミュレーションで、こちらだとメモリーアクセスよりもむしろ演算性能そのものが問題になるのか、VMの数と性能向上があまり関係ない感じになっているが、それでも2~3%の性能改善がみられるとしている。
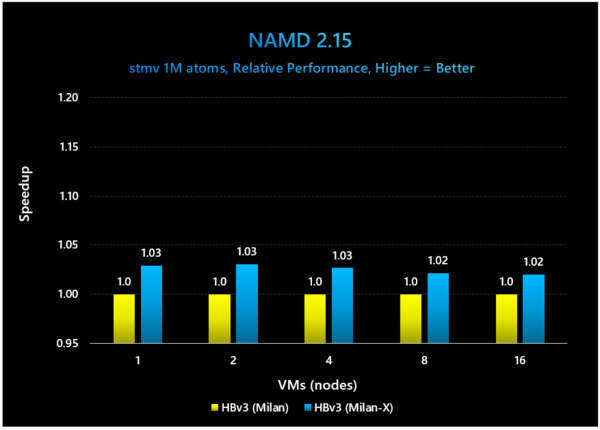
NAMDはイリノイ大学アーバナ・シャンペーン校のTCB(Theoretical and Computational Biophysics Group)などによって提供されるシミュレーション。これは1M個の原子のシミュレーションを行なった場合の性能を比較している
なお、F1レーシングカーモデリングの演算効率(この場合演算性能/コスト)を算出した結果が下の画像である。

VMを増やすことで効果的に性能が上がるので、1VMでやった場合に比べ、64VMでは127分の1の時間で処理が完了し、支払うコストは半分になる(料金はVMの数×VMの使用時間なので、VMの数は64倍でも時間が1/127になることで半減する)という話である
Milanをベースとした数字であるが、Cloudの場合は当然VMの数を増やすと、その分コストが余分にかかる。特にMilanの場合はVMを増やすと相対的にメモリーアクセスが増え、その分実効性能が落ちる結果になっていたが、これがMilan-Xでは大幅に改善された結果、性能は1VM vs 64VMでは128倍になりながら、VMあたりの演算コストそのものは半分に減ったことを表している。
NAMDのようにあまり効果がないものもあるが、CFDなどでは大きな効果があるということも示されたわけで、大量のデータを扱うHPC向けのワークロードでは効果が期待できそうである。
さすがにFrontierはまだ納入の途中ということで、2021年11月のTOP500リストには実行結果などが含まれていないが、2022年6月のリストには入ることは間違いないはずなので、結果が楽しみである。
余談だがその2021年11月のリストには、すでに納入が終わったPerlmutterの結果が示されている。ランキングでは5位でしかないが、例えば4冠を守った富岳が763万848コアの2万9899KWで44万2010TFlopsなのに対し、Perlmutterはわずか76万1856コア、2589KWで7万870TFlopsを実現しており、効率という意味ではPerlmutterの方がずっと高い。
もちろんNVIDIAのA100を大量に実装したPerlmutterと、A64FXだけの富岳を同列で比較するのは間違っているのだが、Milan-XにRadeon Instinct MI250XというFrontierはPerlmutterと似た構成だけに、結果が楽しみである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













