




SRAMはコスト面で実用的でない
そこでHBMにAIプロセッサーを組み合わせる
データアクセスにかかる消費電力の話をしたところでHBM-PIMに話を移そう。Samsungはこうした問題に対し、HBMにAIプロセッサーを組み合わせるという荒業で回答を出した。もともとHBMは、複数のDRAMセルが内蔵されているダイを、HBMのI/Fが搭載されたダイに積層する形で実装されており、それもあって通常のDRAMに比べるとレイアウトにゆとりがある(とは言え、DRAMセルの容量は半減しているが)。
下の画像で左が通常のHBMの構成だが、内部は全部で32バンク(Pseudo Channelが2つあり、それぞれにBank 0~15が属する格好)であるが、そのバンクに挟まれた部分にI/O Controlの領域が結構広めに取ってある。
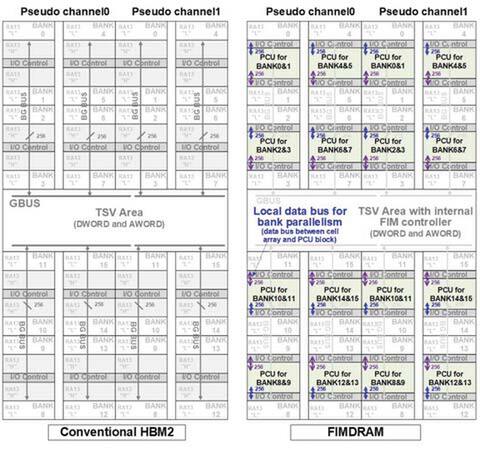
通常のHBMの構成。右のFIMDRAMとはFunction In Memory DRAMの略である
SamsungはこのI/O Controlの領域にPCU(Programmable Computing Unit)と呼ばれる演算エンジンを挟み込んだ。このPCUは隣接する2バンクのDRAM領域にしかアクセスできないという制約はあるが、逆に言えばこの2バンクに対してのみは最小のペナルティーでアクセスが可能とも言える。したがって局所的な演算のみに割り切って使えば、効果的に利用できるわけだ。
DRAMとPCUが混在している構造なので、これを動かすためにはI/F側にも工夫が必要になっている。まずHBMで言えば一番下、HBM I/Fが搭載されているダイに、新しくFIM Controllerが追加される。このFIM Controllerの役割は、CMD Busから送られてくる命令(とアドレス)を解釈し、それがFIMモードの場合にはPCUを動かし、そうでない場合には通常のDRAMセルへのアクセスとする、という制御をする。
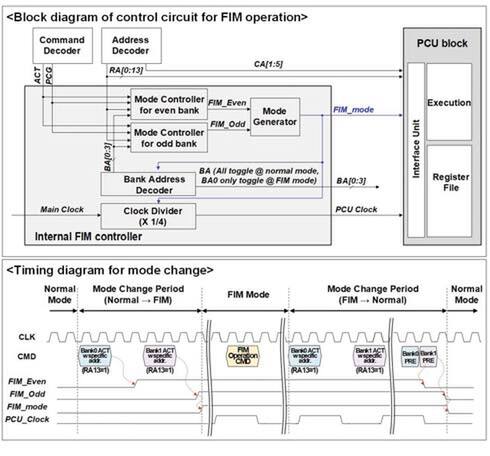
FIMモードの構造。PCUのクロックはメインクロックの1/4というのは興味深い
さすがにHBMに新たに信号線を追加するわけにはいかないので、CMD Busを拡張してFIM用の命令を追加することになる。CMDの命令定義に新しくFIM用のものを追加すると、以下のような動作になる。
- 通常のメモリーアクセス時にはDRAMとして振る舞う
- FIMモード時にはDRAMではなくプロセッサーとして振る舞う
PCUは隣接する2バンクのDRAM領域のみアクセスできると前述したが、その具体的なアクセスモードが下の画像だ。
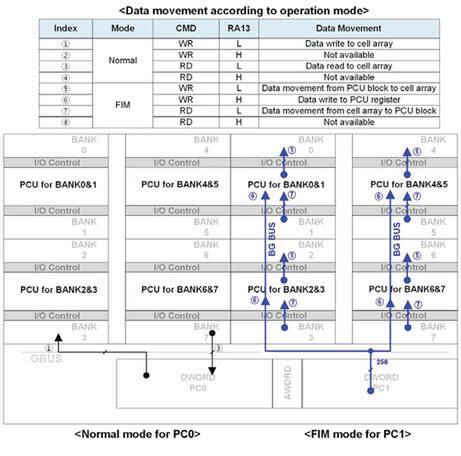
PCUから直接ホストに値を戻すという操作は想定していないので、FIMモードでRD/RA13=Hの操作は定義されていない
ノーマル、つまり通常のHBMとして振る舞う場合は、RA13の信号に関わらず、DRAMセルから読み込む(RD)か、DRAMセルに書き込む(WR)しか処理がないが、FIMモードでは、以下の3種類の動作が可能になる。
- (ホストから)PCUのレジスターに書き込み
- PCUのレジスターからDRAMセルに書き込み
- DRAMセルからPCUのレジスターに読み込み
これで、DRAMセルから値を読み込み、処理後に結果をDRAMセルに書き戻す作業が可能になる。このあたりが自動でないのは、一発で処理が終わる場合もあれば、計算結果をDRAMセルに書き戻す前に次の処理をする場合もあり得るので、全自動にするとむしろ都合が悪いためだろう。このあたりはホストの方からきめ細かく管理してやる必要があるわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ












の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















