




一週開いてのAIプロセッサーだが、今回はCompute-in-Memoryタイプのプロセッサーの話だ。Compute-in-Memoryというと連載591回で紹介したMythicが出てくるが、ここはフラッシュメモリーをそのままアナログ演算器として使うという、分類としてはアナログコンピューターに分類される(そう分類せざるを得ない)構造で、その意味では他と比較できない製品である。
対して今回紹介するのはもっと力業である。今年2月16日、Samsung Electronicsはプレスリリースを出し、HBM(High Bandwidth Memory:高帯域幅メモリー)にAIプロセッサーを組み込んだHBM-PIM(Processing-In-Memory)を開発したことを発表した。このHBM-PIM、今年のISSCC(International Solid-State Circuits Conference:半導体業界最大級の国際学会)でその概略が紹介されたので、これをもとに説明しよう。

プロセッサーが消費電力を費やすのは
6割が演算で4割がデータアクセス
Mythicの時にも説明したが、現在のプロセッサーにおいて少なくない消費電力を費やしているのは、演算ユニットそのものではなくデータアクセスである。下の画像はArmがEthos-N57の発表に先立ち、まだProject Trilliumとして説明されていたころの説明資料である。
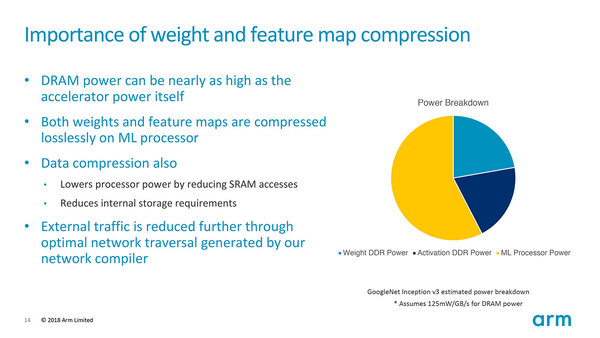
電力の約4割がデータアクセスに費やされる。同じグラフが連載601回にもあるが、細かく前提条件などが載っているこちらの方がわかりやすいだろう
機械学習における推論処理を行なうにあたって、全体の6割がプロセッサーそのもので、2割が重み(Weight)を格納するデータアクセス、残りがアクティベーションのためのアクセスに費やされているとしている。
実はAIプロセッサーの場合、相対的に演算処理の比率が高い。なにせ処理がほぼ固定されており、また演算データ量が相対的に少ない(推論では8bit幅ということも多い)ため効率が上がるという話であり、これが倍精度のFPUなどになると演算処理に費やす消費電力と同等以上をデータアクセスに費やすという報告もあったりする。
これはDRAMから遠い所に演算器があるから悪い、という話でもある。要するにDRAM Cell→DRAMチップ内のI/F→ホストへの配線→ホスト側DRAM I/F→内部バス→プロセッサーのデータキャッシュ→レジスターファイル、という遠い道のりを経てDRAMのデータをプロセサーで扱えるようになるから、それは消費電力が増えるのも無理もない。
ArmのEthosの場合は、このDRAMアクセスへの消費電力の多さ、それとレイテンシーを嫌って大容量のSRAMを突っ込んでカバーした形だ。これはCerebras SystemsのWSEなども同じで、AIプロセッサーとしては定番であるのだが、これの欠点はエリアサイズの肥大化である。
そもそもDRAMの場合、1bitの記録にはトランジスタ1個で済むのに対し、SRAMは最低でも4個(ただ4T SRAMは信頼性などの問題もあるため、通常は6つ以上のトランジスタを使う)必要になる。同じサイズの容量を確保するのに、DRAMに比べて最低4倍(実際には6倍以上)の面積を喰う格好だ。DRAMとSRAMで製造プロセスが異なる(SRAMの方が微細化できる)ことを考えても、まだ2~3倍の差は軽くある。
加えてDRAMの場合は大量生産に特化しているためコストそのものは安いが、SRAMは(特にAIプロセッサー向けの先端プロセスの場合)、結構なコストになる。容量あたりのコストを比較すると、SRAMはDRAMよりもおそらく1桁上がることになるだろう。このコスト面の不利さをどう補うか、がテクニックの見せどころになっていたわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












