




圧倒的に高い性能を低い消費電力で実現
TENSAIの中身だが、構造自身はいたって常識的だ。マイコンのコアそのものはArmのCortex-M3という、おそらく世界で一番多いMCU(*2)で、それにDual MACのDSPと64KBのSRAM、それと周辺機器を組み合わせているだけだ。
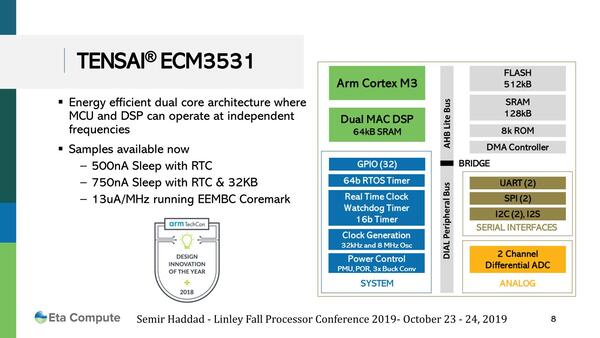
TENSAI EMC3531の構造。このうちCortex-M3コアと、図で緑色のSYSTEMブロック、茶色のSerial Interface、黄色のAnalogの各ブロックはサブスレッショルドで動作可能と思われる。DSPもそうなっている可能性はあるが、明言はされていない
実はこのDSPは、NXPのCoolFluxという、もともとはオーディオ処理用のDSPのライセンスを受けて実装しているものだ。構成はDual 16bit MAXとあるので、おそらくDSP16というタイプのものだろう。こちらもライセンスを受けたものなので内部構造そのものは一切手を入れられない。
ただETA Computeの場合、デジタル技術よりもアナログ技術に強みがある。具体的に言えば、IPとして提供されたもの(つまりRTLそのもの)には手は入れられないが、それを物理実装する際に独自のノウハウを注ぎ込める。
もともと2017年に発表したIPがまさしくそうしたものであり、TENSAIチップにもそうしたノウハウは注ぎ込まれた。
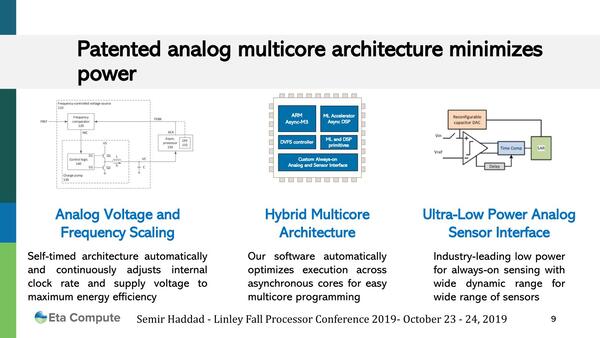
1つ目は動作周波数に応じて電圧を可変する仕組みだが、インテルのSpeedStepなどと異なるのはこれをアナログで処理していることで、さらにそもそもサブスレッショルドでも動作するような(やはりアナログ的な)工夫も含まれている
この結果として、CPUコアは他社製品と比較して圧倒的に高い性能を、しかも低い消費電力で実現できているとする。
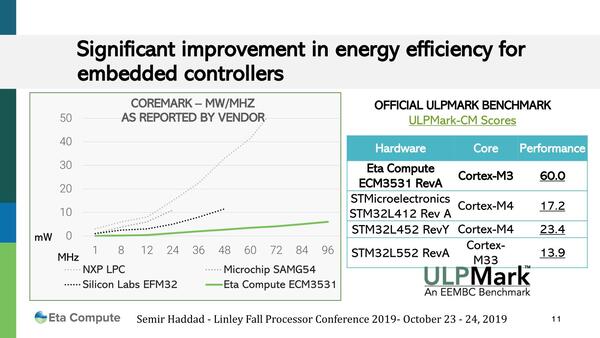
比較対象はいずれもArmのCortex-Mシリーズを搭載する製品である。比較に利用されたのは、EEMBCのULPMarkという業界標準のベンチマーク
同じ動作周波数であってもより低い消費電力で動作するのであれば、逆に言えば従来のMCUでは性能や消費電力の壁にあたって性能が出せないという場合でも、TENSAIコアでは切り抜けられることになる。
またDSPはもともとCNNの実行に都合が良い、という話は前回もご紹介した通りだ。実はArmも、Cortex-M4の世代からDSP命令と呼ばれる命令拡張を追加しているが、これはいわば「DSP風」命令であって、実際の性能はDSPにはおよばないし、なにより消費電力が圧倒的にDSPより多くなる。
前回のCEVAもそのあたりを差別化要因として、「Armコア+CEVAのDSPという形で性能と消費電力のバランスを改善できますよ」という売り方をしている(*3)。
ETA ComputeもやはりCoolFluxを組み合わせているが、特徴的なのはCPUコアと非同期なことだ。これにより、例えばDSPでCNNのネットワークをブン廻している間はCPUの動作周波数を下げたり待機させたりすることで、省電力化が狙えることになる。

CPUコアとDSPは非同期。InterruptやMailboxなどはCPU側へのオーバーヘッドが大きいし、RPCはレイテンシーが問題になることが多いのだが、このあたりをどう解決しているかは興味あるところだ
ETA Computeの説明によれば、STMicroのMCUをCPUコアだけで処理した場合に比べ、75倍の性能効率向上が図れたとしている。
CIFAR10は32×32ピクセルという非常に小さな画像を利用しての物体認識だから、MCUには手頃(ただし実用性は「?」)なネットワークであるが、TENSAIでは画像の読み込みやそのロードと最後の処理をCortex-M3コアで、3層の畳み込みはCoolFlux DSPで行なうという形で作業を分担している。
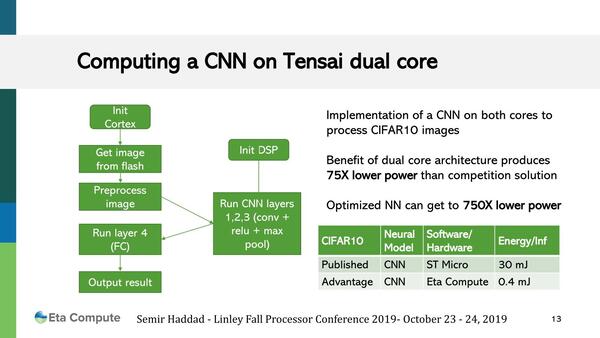
最適化したからといってさらに10倍も効率上がるのだろうか?
CIFAR10以外のAIアプリケーション例として示されたのが下の画像だ。とにかく圧倒的に少ない消費電力でAIアプリケーションを駆動できるというのがTENSAIチップの最大のアドバンテージである。この省電力性を生かして、Extreme Edgeでもっとさまざまな計算処理をさせられるというのが同社の説明であった。
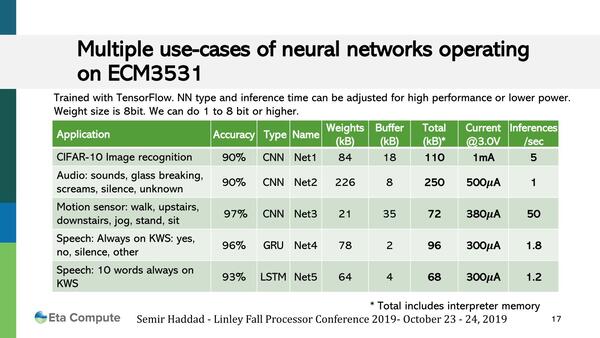
CIFAR10以外のAIアプリケーション例。3V駆動で1mAでは3mW、500μAでは1.5mWほどになる。最後の項目が速度(Inferences/sec)であり、CIFAR-10の画像認識なら1枚あたり0.6mWsec=0.6mJ、2番目のオーディオ処理なら同様に1.5mJ。以下0.023mJ、0.5mJ、0.75mJという計算になる
(*2) Cortex-Mシリーズの最初の製品。ベストセラーというか、ロングセラーというか。ただ微妙なのは、その後で出たCortex-M0(廉価版)の方が、価格が安い分ひょっとすると上かもしれないところ。このあたりの集計はArmも出してくれていない。
(*3) Arm TechConにはしばしばCEVAがブースを出しており、「御社はArmの競合じゃないの?」と話を振ったら「いやいや、ウチはあくまでもDSPのIPを提供するだけで、汎用的な処理はMCUなりMPUが必要で、そこはArmに任せた方がいい。だから補完関係にあるわけで、Armさんとは仲良くやっていきたいですよ(棒)」という返事が。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























