ロードマップでわかる!当世プロセッサー事情 第590回
Radeon Instinct MI100が採用するCDNAアーキテクチャーの内部構造 AMD GPUロードマップ
2020年11月23日 12時00分更新

CDNAはRDNAにかなり近いが
SIMDエンジンをHPC向けにチューンしている
個々のCU(CUDA 1.0ではXCUという名前になっている)の構造が下の画像である。1つのXCUに64個の演算ユニットが実装されるという構図はGCNやRDNAと同じであるが、GCNとの比較で言えば以下の違いがある。

XCUの構造。この64個の演算ユニットが16WideのSIMD構成であることそのものは以前と同じ

こうしてみると基本的なコンセプトはRDNAとかなり近いが、SIMDエンジンの内容をHPC向けにした感じである
- FP64/FP32のサイクル当たりの処理性能(Vector FP32/FP64)は同じ(FP64で64Flops/サイクル、FP32で128Flops/サイクル)
- 新たに行列演算を高速化するMatrix Unitと呼ばれる仕組みが入り、これを利用することでFP32だと2倍(256Flops/サイクル)の処理性能になる
- FP16は、GCNだとFP32の2倍(256Flops/サイクル)なのに対し、CDNA 1.0ではこの4倍の1024Flopsサイクルで演算可能
- 新たにBFloat16をサポート。演算性能は512Flops/サイクルになる
XCUはこの演算ユニット4つで構成されるので、1CUあたりFP64で256Flops/サイクル、FP32だと512~1024Flops/サイクル、BFloat16で2048Flops/サイクル、FP16なら4096Flops/サイクルになる計算だ。
フロントエンドを含む全体の構成が下の画像だ。RDNAの構成と比較すると、RDNAがWave32での管理となっており、2つの16-Wideをまとめて32-WideのSIMDとして扱う関係か、Wave Controllerは20 Waveになっているのに対し、CDNAではおそらくGCN同様に64-Waveでのハンドリングしていると思われ、Wave Controllerは10 Waveになっているのが目立つ違いである。Vector Registerの数などはRDNAと共通になっている。
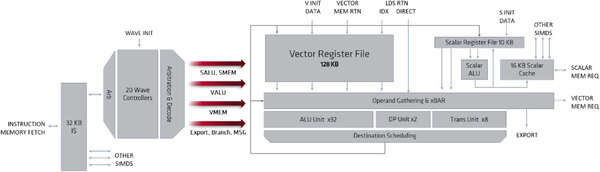
こちらはRDNA(RDNA2ではない)の内部構造。Scalar Registerが10Kあるのが目立つ

RDNAのダイ写真。どういう理由か知らないが、AMD提供のこの画像は妙に解像度が低い

こちらのダイ写真は斜めになり、しかも妙な映像効果付きであるが、高解像度のものに歪み補正をかけたもの。したがって縦横比は正確ではない
さて、先のCDNA 1.0の構造を示す画像によれば、CDNA 1.0はこのXCUを複数個まとめたグループを8つ搭載することになる。Radeon Instinct MI100の仕様によればXCUは120個なので、グループあたり15個のXCUが含まれる計算になるのだが、実際にダイ写真を見ると、16個のXCUが含まれていることがわかる。
つまりハードウェア的には128XCU、8192個のStream Processorが実装されており、このうち120XCU、7680個のStream Processorのみを有効にしているとわかる。

前述のダイ写真の左上を切り出してナンバーを振ってみた
この理由は後述するダイサイズに関係する。CDNA 1.0は過去最大規模のダイサイズであり、それなりに欠陥を含んでも対応できるように、冗長XCUを8つ用意したというあたりであろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












