



ロードマップでわかる!当世プロセッサー事情 第579回
Tiger Lakeの内蔵GPU「Xe LP」は前世代のほぼ2倍の性能/消費電力比を実現 インテル GPUロードマップ
2020年09月07日 12時00分更新

わりとパッケージサイズが大きい
Xe HP
Hot Chipsでは、これに加えてXe HPなどについてのプレビューも公開された。中央に置かれたバッテリーが単三電池相当だとすれば、パッケージサイズは52.8×81.3mmという結構大きなものになりそうだ。

Xe HP。これは2タイルのものと思われる
Xe HPのダイが、ちょうど裏面のパスコンの真上に位置していると仮定すると、ダイサイズは23.4×22mmで514.8mm2という計算になる。GPGPU向けとしては手頃なサイズではないだろうか?
このXe HPは1/2/4Tile構成がある、という話は連載569回でも明かされていた。演算性能はFP32換算で1Tileあたり10TFlops、4Tileのもので40TFlopsとなる。
Int 8だとすると320Topsで、Raja氏のツイートに出てきた“(だいたい)1Pops”には遠い気がするのだが、どういう計算なのだろう?

このXe HPとXe HPCの(プロセス以外の)差が実はよくわからない。Xe HPにRAMBO Cacheなどを組み合わせたのがXe HPCというふうに筆者は理解しているのだが、間違っている可能性もある
TSMCの5nmは2021年末までに本当に間に合うのか?
最後に製造プロセスだが、Xe LPは10nm SuperFinで、これはいい。そして連載569回に出てきたサンプルは10nm Enhanced SuperFinである。これは来年の投入であろう。
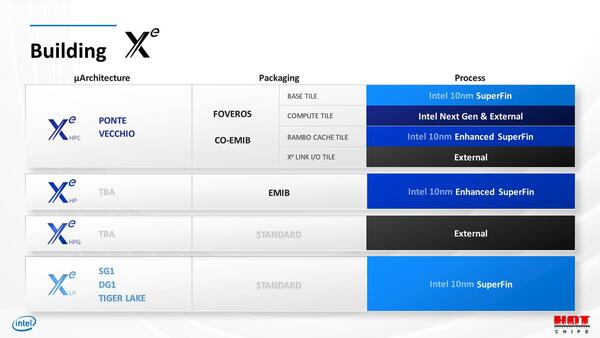
Xe LPのプロセスは10nm SuperFinだが、Ponte Vecchioはインテルの7nmかTSMCの5nmということになる
問題はPonte Vecchioで、Compute TileはIntel Next Gen & Externalというのは、要するにインテルの7nmかTSMCの5nmという話だ。Xe Link I/O TileはExternalだが、これはそれこそTSMCの6nmや7nmあたりだろう。
そしてRambo Cacheが10nm Enhanced SuperFinということで、そうなるとAuroraが予定通りに稼働しない公算が出てきた。連載435回で触れたが、Auroraは本来なら来年の今頃には設置が始まり、2022年末に検収完了となるはずだった。
ところがPonte Vecchioの要素の中でこれも確実に間に合うのはBase Tileと、Rambo Cacheがなんとかというあたりで、肝心のCompute TileがTSMCの5nmで本当に間に合うのか? という話である。
プロセスそのものはもうだいぶ安定してきたらしいが、はたして2021年末までにインテルの希望する数量の出荷ができるのか? はかなり不明確である。すでにインテルがTSMCの5nm向けCompute Tileをテープアウトしている、というのであれば可能だと思うが、テープアウトが来年だとかなり厳しいだろう。
またXe HPGは初めから外部Fab頼りになっており、それこそこれもTSMCの5~6nmあたりがターゲットではないかと思うが、こちらもどんなものになるのか、まだ見えてきていない。このあたり、今年中に何か動きがあるとおもしろいのだが。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












