



ロードマップでわかる!当世プロセッサー事情 第873回
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃
2026年04月27日 12時00分更新

GTC 2026アップデートの3回目となる今回は、2028年のロードマップについて説明しよう。実は基調講演の中で2028年、つまりFeynman世代についてはあまり詳細な説明はなかった。ロードマップとして示されたのが下の画像だ。

NVIDIAのロードマップ。さりげなく2026年にNVL576がOberonベースで実現することになっているのが特記事項である
2028年の部分を拡大してみると、以下のことが明らかになった。
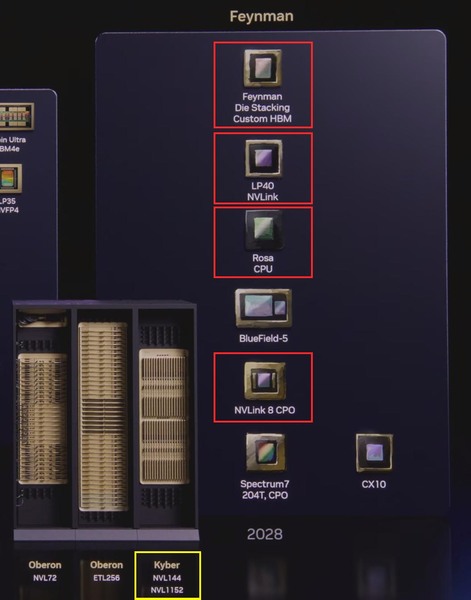
2028年のロードマップ。BlueField-5の存在やSpectrum7がしれっと204Tbpsと書いてある。これはこれで問題なのだが。さらにConnextX-10の存在も予告されている
- FeynmanはDie StackingとCustom HBMを採用
- LP40がNVLinkを搭載
- CPUがVeraからRosaに更新
- NVLink 8にはCPOが用意される
それに加え、
- KyberベースでNVL1152が投入される
以下これを順に説明していく。
Feynmanの鍵を握る「Die Stacking」と「COPA」構想
まずFeynman。基調講演の中では名称が呼ばれただけで、基調講演の後のQ&Aでも特に言及がなされていない。したがってDie StackingとCustom HBMを使うこと「だけ」が公開情報になる。
このDie Stackingであるが、これに関してNVIDIAが2021年に発表した"GPU Domain Specialization via Composable On-Package Architecture"という論文がある。

NVIDIAが2021年に発表した論文。ある意味出オチというか、右上の図がすべてを物語っている
COPA(Composable On-Package Architecture)というのは、従来のGPUの構成をモジュールレベルで分解し、必要に応じて組み合わせを変えることで、用途別(Domain Specific)な製品を構築しよう、というものである。
動機は、HPC向けとAI向けではGPUに対する性能要求が異なるところからスタートする。プロセス微細化にともない演算器を大量に集積できるようになり、特にDeep Learning向けのスループットはどんどん向上している。一方でダイサイズはReticle Limitにより制限され、またメモリー搭載量やメモリー帯域はプロセス微細化の貢献が薄い。結果、今後は演算性能に対してメモリー帯域が決定的に不足するという予測になった。
悪いことに、このメモリー帯域の不足はアプリケーションによって影響が異なる。NVIDIAの分析によれば、Deep Learningの訓練/推論はDRAM帯域がボトルネックになっており、実行時間の28~30%がDRAM帯域の制限に由来すると予測される一方、HPCアプリケーションでは仮に帯域を無限にしても性能は5%ほどしか向上しないという結果が出たという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












