



ロードマップでわかる!当世プロセッサー事情 第579回
Tiger Lakeの内蔵GPU「Xe LP」は前世代のほぼ2倍の性能/消費電力比を実現 インテル GPUロードマップ
2020年09月07日 12時00分更新

このロードマップ連載もすでに579回、第1回から数えると11年を超えて12年目に入るわけだが、その中でインテルのGPUというテーマで取り上げるのはこれが最初である。
もちろんLarrabeeなどは扱ったし、チップセットの絡みでG965の回で部分的に触れたりはしたが、(GPGPUではなく)GPUとして扱うのはこれが初めてだったりする。ということで、今回は少し昔の話から。
16のExecution Unitで構成される
XeのSubslice
下の画像はXeに至る道ということで、Gen1(Intel 740のことだ)~Gen11を経てTiger Lake世代からXeに切り替わるという歴史を語っている。

Gen2は当初Intel 752/754として外付けで発売予定だったが、あまりにGen1(Intel 740)の評判が悪かったためにキャンセル。このグラフィックコアを流用したのがIntel 810やIntel 815である
さてそのXeだが、以前はXe LP/HP/HPCの3種類しか存在しなかったのが、今回Xe HPGというエンスージアスト向けGPUがラインナップに加わったことが明らかにされた。
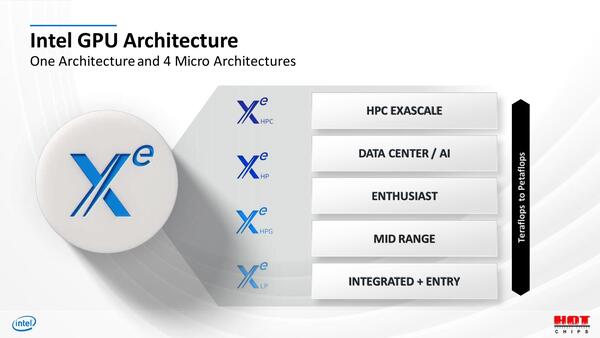
もっとも連載472回で紹介したどうみてもただのモックアップな画像を鑑みるに、エンスージアスト向けは最初から既定路線で、一時的にひっこめていただけかもしれない
そのXeの基本構造がこちら。各々のユニットをどの程度内蔵するかはSKUによって当然変わってくる。
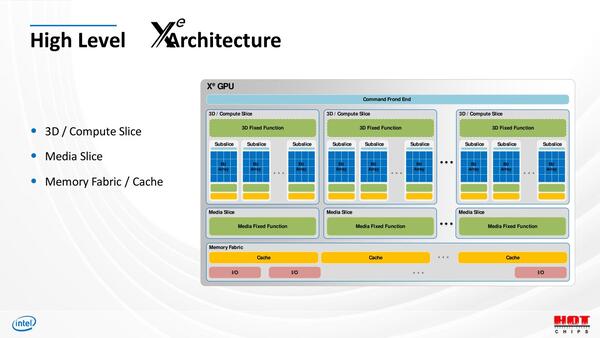
基本構造そのものはXe LPからXe HPCまで全部一緒である
まず3D/Compute Sliceの構造がこちら。Subsliceの数も変更可能になっている。
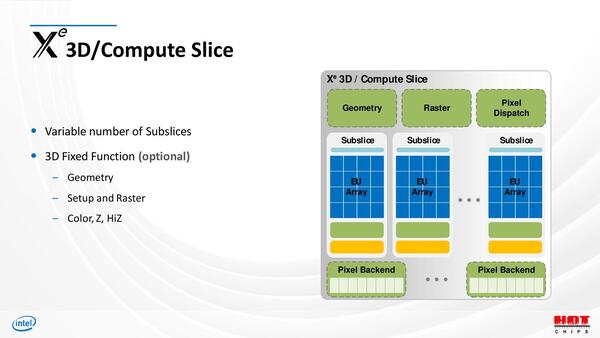
3D/Compute Sliceの構造。HPC向けでは、Geometry/Raster/Pixel DispatchやPixel Backendなどは省かれると思われる。HPはどうなんだろう?
おのおののSubsliceの構造がこちら。16EU(Execution Unit)とキャッシュ、Thread DispatchとLoad/Storeユニットは共通で、SamplerやRay Tracing Unitはオプション扱いである。
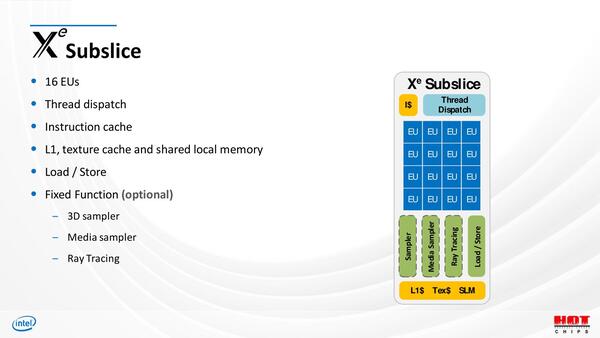
Subsliceの構造。このRay Tracing Unitの詳細は今回は一切明らかにされていない。おそらくはXe HPG向けと思われる
下の画像がEUの詳細だが、これだとややわかりにくいかもしれない。
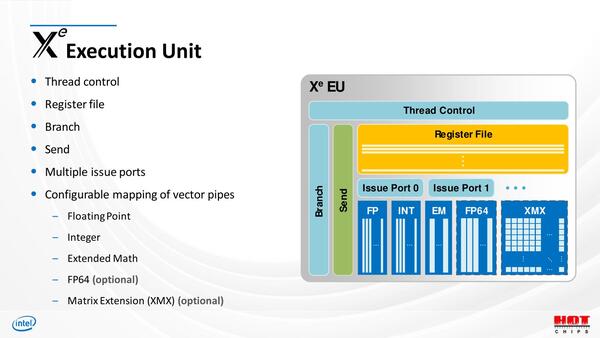
EUの詳細。XMXは、おそらくであるが連載569回で紹介したAMXに対応するもの(CPU側がAMX、GPU側がXMX)と思われる。つまりXe GPUがCPUのアクセラレーターとしてシームレスに連携して動くと期待される
下の画像2つはArchitecture Dayの資料だが、Gen11までのEUは4-wideのFP/Int ALUと同じく4wideのFP/Extended Math ALUの組み合わせになっており、これを利用することで最大8wideの演算が可能であったが、ただしExtended Mathが発生すると右側のエンジンはそれに占有されてしまうので、4wide相当に性能が落ちることになる。
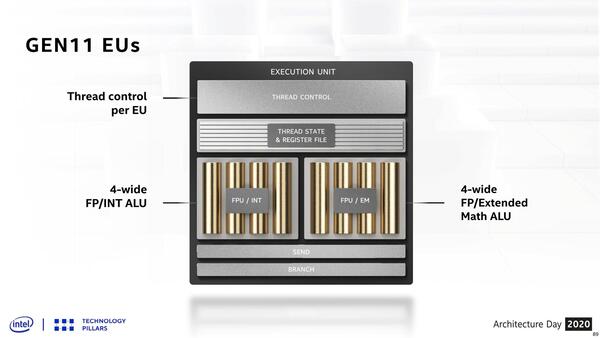
Gen11 EUの場合、1サイクルあたりFP32とInt32のMAC演算なら16FLOPS、FP16なら32FLOPSの演算だった。積和(=1演算が2FLOPS)での数字なので、要するに8本の演算パイプがフル稼働する形である

Gen11とのもう1つの違いは、Gen11はEUごとにThread Controlが独立しているが、Xeでは複数EUを横に貫く形でまとめてThread Controlが行なわれている。これで、スレッド制御がより効率的に行なえるとしている
対してXeでは、8wideのFP/INT ALU+2wideのExtended Math ALUという構成になり、Extended Mathと並行して8wideのALUが動作することになる。
したがってピーク性能そのもので言えばFP32やInt32が16FLOPS、FP16では32FLOPSということでGen11世代と違いはないが、実効性能はやや引き上げられた形になる。
ちなみに、ここに出てくるDP4Aの処理は下の画像のようなもので、Dot Product(ドット積)の計算の際に利用される。Xe EUはこれを8wideで実行できるわけだ。
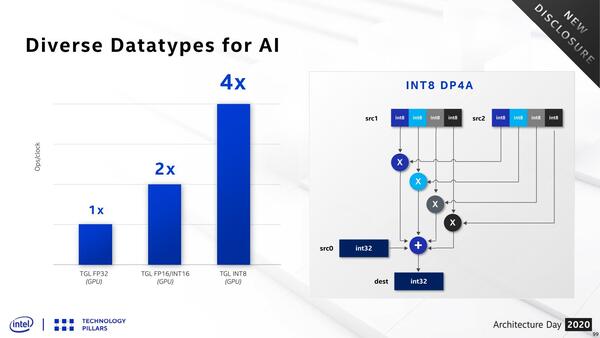
右がDP4Aの演算シーケンス。左は純粋にTiger Lakeでデータサイズを小さくするとその分演算性能が上がることを示している
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












