
Radeon Instinctは
Tesla V100とほぼ同等の性能
ちなみに簡単な性能比較も示され、DGEMM、機械学習の推論、学習などで、NVIDIAのTesla V100とほぼ同等の性能を発揮することがアピールされた。以下もう少し細かく説明したい。

DGEMM(FP64でのGEMM)。Vega 10と比較して8.8倍もの性能アップ

Tesla V100との比較。Tesla V100の場合、NVLink版の方が少し性能が高いことを考えると、NVLink版のTesla V100と同等といったあたり

RESNET-50を利用しての推論フェーズ。Radeon Instinct MI60では毎秒500枚近い画像の認識が可能になるとする
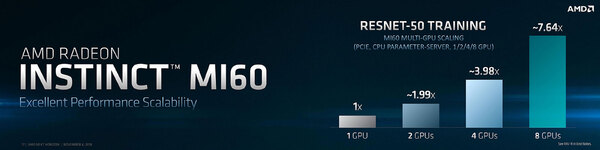
そのRESNET-50を利用しての学習フェーズでのスケーリング。8枚接続でも7.64倍(効率95.5%)は確かに良い

Tesla V100との比較では若干見劣りするが、大きくは変わらない
まずVega 20の構成であるが、基本的にはVega 10とまったく変わらない構成となる。NCUは64個で、1つのNCU内にSPを64個搭載するという構成も同じなので、SP数は4096個で横並びとなる。では何が変わったかというと、1つはFP64のサポートである。
前述の表にVEGA 10ベースのRadeon INSTINCT MI25の数字も入れてある(動作周波数、およびInt 8の性能は公式に発表されていないので、筆者の推定である)が、FP16/FP32に関してはMI25も含めておおむね動作周波数×SP数の比に近い性能が出ているのに、FP64ではMI25のみ落ち込んでいたのは、FP64のハードウェアがVega 10では実装されておらず、ソフトウェアで実施していたためである。
Vega 20ではこれがハードウェアで実装できるようになり、結果FP32のほぼ半分の性能が得られるようになった。実装としては、FP32の演算器2つでFP64を実行できるという効率を重視したものである。
なお、Tesla V100はFP32とFP64で別々の演算器を搭載するという実装になっており、どちらが良いというものではないにしても、Tesla V100のダイが巨大化した理由の一因はここにあると考えていい。
ちなみにサポートしたのはFP64のみならず、INT 4やINT 1もサポートしたという話であり、しかもMixed Precisionという、入出力は例えばINT 4やFP16で、途中の演算がINT 8とかFP32といった、複数の精度を組み合わせる処理にも対応するとしている。このあたりはそれぞれのSPの内部構造に変更が加えられたことになる。
逆に言うと、INT 8やFP32での演算性能改善に関しては、単に動作周波数の差以上のものはないというのがVega 20の特徴でもある。これはゲーミングGPUに転用するにはやや厳しいところではある。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ











