
Infinity Fabricの
信号速度は50Gbps

あいにくこの写真を撮った時は時間がおしていて、Wang氏にこのポートはなんなのかを聞けなかった
次にInfinity Fabricの話をしよう。上の画像はサーバーシャーシにRadeon Instinct MI60を8枚装着した構成だが、4枚のRadeon Instinct MI60の上に結構大きな板が載っているのがわかる。その板は下の画像のような感じだ。

Infinity Fabricでの相互接続は最大でも4枚となっており、このケースのように8枚構成だと、2つの4枚の塊をPCI Expressでつなぐ形になる
説明によれば信号はx16構成ということなので、信号速度は50Gbpsという計算になる。下の画像が妙に頑丈なシールド構成になっており、しかも途中にバッファらしきものが入っているのは、50Gbpsで信号を通すためだとすれば納得がいく。

全体的にカバーが掛けられていて、実際の配線などは見えないようになっていた。カバーというよりもシールドなのかもしれない。妙に幅広なのは、おそらく配線と配線の間にクロストーク防止用のGNDラインをたっぷり含んでいるためと思われる
このInfinity Fabricであるが、説明によれば双方向ではあるが、構成はRing Busになっているという話であった。要するに上の画像のコネクターは、内部的には図のような配線になっている模様だ。
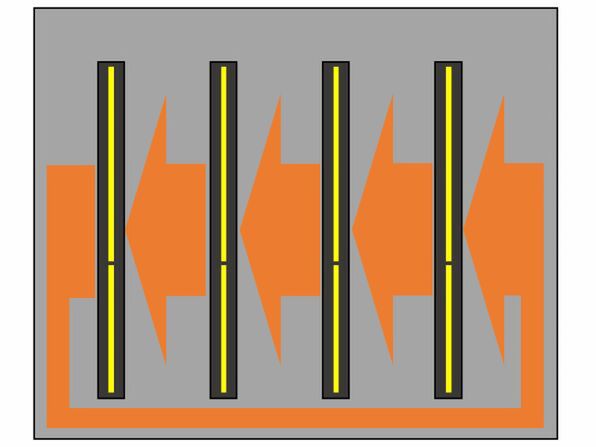
Infinity Fabricの配線
Radeon Instinct MI 50/60側は送信/受信ともに100GB/秒(50Gbps×16)で行なう格好である。この構成の場合、隣接するノードに最短だと1hop、最長だと3hopで通信することになるあたり、二重リングになっている可能性もある(そのあたりまで突っ込んでは教えてくれなかった)が、逆に最大でも4枚に限っているから、レイテンシはあまり気にしなくても良いと判断した可能性がある。
ところでInfinity Fabricで接続するということは、逆に言えばキャッシュコヒーレンシが保たれるという意味でもあり、さらに言えば4枚のRadeon Instinct MI50/60に搭載される16/32GBのメモリーが、それぞれ別のアドレス空間にマッピングされることになる。
ということは、このInfinity Fabricを経由して、あるRadeon Instinct MI50/60に搭載されたVega 20コアが、別のRadeon Instinct MI50/60に搭載されたメモリーにアクセスすることも可能になるはずである。実際確認したところ、これは可能という話であった。NVIDIAもUnified Memoryという形でNVLink経由でのメモリー共有をサポートしているが、この点でも並んだことになる。
GPU同士をInfinity Fabricで接続するなら、CPU⇔GPU間もInfinity FabricあるいはCCIXでつないでしまえば、もっと帯域が上がるうえにキャッシュコヒーレンシが取れるのに、という気もするのだが、確認したところ「ROCmが対応してないから無理」という話であった。デバイスドライバーの構造も大幅に変わらざるを得ないため、そうそう簡単には話が進まないのだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












