
Radeon Instinctは
Tesla V100とほぼ同等の性能
ちなみに簡単な性能比較も示され、DGEMM、機械学習の推論、学習などで、NVIDIAのTesla V100とほぼ同等の性能を発揮することがアピールされた。以下もう少し細かく説明したい。

DGEMM(FP64でのGEMM)。Vega 10と比較して8.8倍もの性能アップ

Tesla V100との比較。Tesla V100の場合、NVLink版の方が少し性能が高いことを考えると、NVLink版のTesla V100と同等といったあたり

RESNET-50を利用しての推論フェーズ。Radeon Instinct MI60では毎秒500枚近い画像の認識が可能になるとする
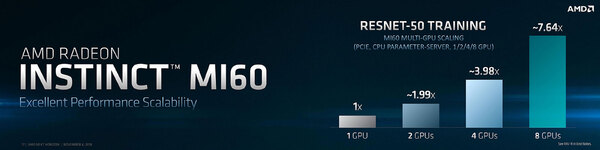
そのRESNET-50を利用しての学習フェーズでのスケーリング。8枚接続でも7.64倍(効率95.5%)は確かに良い

Tesla V100との比較では若干見劣りするが、大きくは変わらない
まずVega 20の構成であるが、基本的にはVega 10とまったく変わらない構成となる。NCUは64個で、1つのNCU内にSPを64個搭載するという構成も同じなので、SP数は4096個で横並びとなる。では何が変わったかというと、1つはFP64のサポートである。
前述の表にVEGA 10ベースのRadeon INSTINCT MI25の数字も入れてある(動作周波数、およびInt 8の性能は公式に発表されていないので、筆者の推定である)が、FP16/FP32に関してはMI25も含めておおむね動作周波数×SP数の比に近い性能が出ているのに、FP64ではMI25のみ落ち込んでいたのは、FP64のハードウェアがVega 10では実装されておらず、ソフトウェアで実施していたためである。
Vega 20ではこれがハードウェアで実装できるようになり、結果FP32のほぼ半分の性能が得られるようになった。実装としては、FP32の演算器2つでFP64を実行できるという効率を重視したものである。
なお、Tesla V100はFP32とFP64で別々の演算器を搭載するという実装になっており、どちらが良いというものではないにしても、Tesla V100のダイが巨大化した理由の一因はここにあると考えていい。
ちなみにサポートしたのはFP64のみならず、INT 4やINT 1もサポートしたという話であり、しかもMixed Precisionという、入出力は例えばINT 4やFP16で、途中の演算がINT 8とかFP32といった、複数の精度を組み合わせる処理にも対応するとしている。このあたりはそれぞれのSPの内部構造に変更が加えられたことになる。
逆に言うと、INT 8やFP32での演算性能改善に関しては、単に動作周波数の差以上のものはないというのがVega 20の特徴でもある。これはゲーミングGPUに転用するにはやや厳しいところではある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ








