



レイトレーシングにDLSS、RTコアやTensorコアの役割、自動OCテスト機能まで!
Turingコアの構造も謎の指標「RTX-OPS」の計算方法も明らかに!徐々に見えてきたGeForce RTX 20シリーズの全貌
2018年09月14日 22時00分更新


「リアルタイムレイトレーシング」というCG界の“聖杯”を手にすれば、今までの「ラスタライズ法」では困難だった表現も容易に実装できるという。この聖杯にいち早く手をかけたのは、新アーキテクチャー「Turing」をベースにした「GeForce RTX 20シリーズ」を生み出したNVIDIAだ。
8月にドイツはケルンで催されたスペシャルイベント「GeForce Gaming Celebration」にて初めてRTX 20シリーズがお披露目されたが、その直後にプレス関係者向けの説明会「Editor's Day」が設けられ、さらに深いレベルでの話を聞くことができた。
本日(9月14日)情報が解禁されたので、前回の記事「CG界の聖杯「リアルタイムレイトレーシング」に手をかけたGeForce RTX 20シリーズを理解する」【前編】【後編】お伝えできなかったことや後から判明したことを含め、RTX 20シリーズの技術的側面について深掘りしてみたい。
フルスケールな「TU102」コアの構成
まずはTuringコアの構造から眺めていこう。「GeForce RTX 2080 Ti」のコアは「TU102」、「GeForce RTX 2080」が「TU104」、そして「GeForce RTX 2070」は「TU106」と、それぞれ別の設計が用意されている。
Pascal世代であるGTX 1080と1070はどちらも同じGT104から生まれた製品であり、末尾「6」の製品はミドルレンジ向け(この場合はGTX 1060)であったことを考えると、今後GeForce RTX 2060が出るとすれば「TU107」になるのだろうか?
まずは“フルスケール”なTU102のダイアグラムをチェックしてみよう。まず、SM(Streaming Multiprocessor)あたりCUDAコアは64基、Tensorコアは8基、RTコアが1基ずつ配置される。CUDAコア数はPascal世代から半減したが、FP32とINT32用の演算機の2つで1カウントになっていること、Tensorコア8基の存在などから、Voltaの発展形であることが読み取れる。
Turingダイ内部の回路。どの部分がどの機能かは明言されていないが、中央上下がL2キャッシュ、その左右に無数に見えるパターンがSMと考えてよいだろう。
1番大きな改善はFP32とINT32の演算機を分割したことだ。ゲームのシェーダー処理においては、FP32とINT32の処理が混在している。Pascal世代までのアーキテクチャーでは、SM内でINT32の処理を実行している際、アイドル状態のCUDAコアがあってもFP32の処理をさせることはできなかった。
だが、Turing(とVolta)ではFP32とINT32のデータパスを分けることで、両者の処理を並列で捌けるようになる。ゲームによってINT32ラインの使われ方は異なるが、NVIDIAは10~50%のスループット向上を見込めるとしている。
ちなみにVoltaではFP64用のユニットがSMあたり32基搭載されていたが、TuringではSMあたり2基、演算性能にしてFP32の32分の1のスループットになっている。これについて、NVIDIAはFP64を減らしたことで「どんなプログラムでもFP64コードを正しく実行できるようになる」と説明している。
そして、Volta世代とTuring世代の最大の違いは、SM1基ごとにRTX 20シリーズの核心技術、RTコアが搭載されていることだ。このRTコアの役割については後ほど詳しく解説することにしよう。
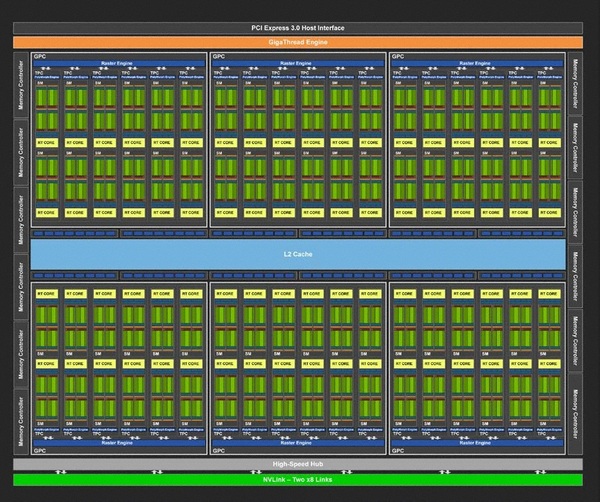
フルスペックTU102のブロック図。RTX 20シリーズに先立ち発表された「Quadro RTX 8000」はこのような構造になっている。
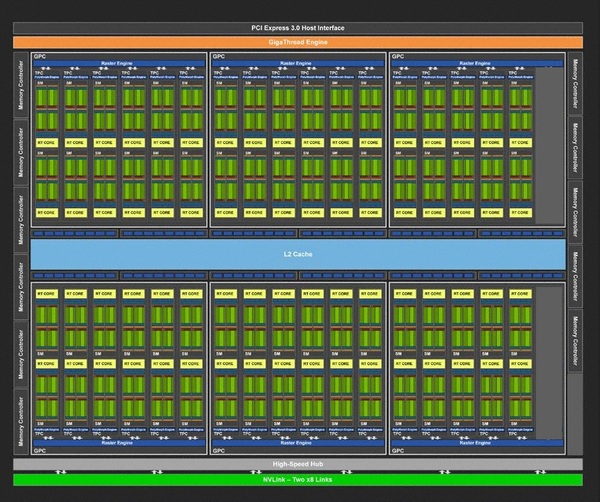
公式スペックをベースにしたRTX 2080 Tiのブロック図(筆者による想像)。SM4基、メモリーコントローラー1基が無効化されていると推測される。無効化された回路の位置は実物と異なる可能性がある。
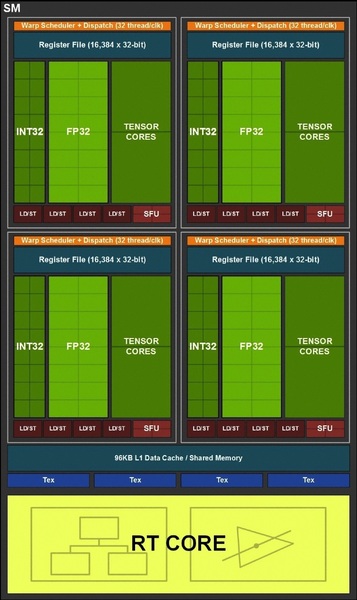
Turing世代のSMの構造。CUDAコアはFP32とINT32に分割され、各々16基+Tensorコア2基がスケジューラーで形成した小クラスターが4つ。そこにRTコアなどを追加したものでSMとして運用される。図にはFP64の演算機は省略されているが、SMあたり2基組み込まれている。RTコアの背景に意味深なアイコンが描き込まれているが、それは後ほど解説しよう。
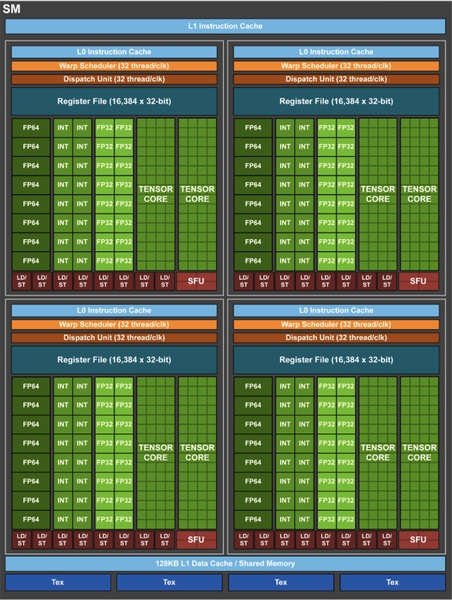
Volta世代のSMの構造。FP32とINT32を分割することで、両演算を並列処理できるのはこの世代から。FP64の演算機が32基あること、L1データキャッシュ(共有メモリー兼用)の量が微妙にTuringより多いなど、TuringはVoltaの完全上位ではない点に注目。

Pascal世代のSMの構造。この世代のCUDAコアはINT32演算もできるが、基本はFP32演算に特化した設計だ。また、SM単位で共有されるL1キャッシュと共有メモリーが独立している。
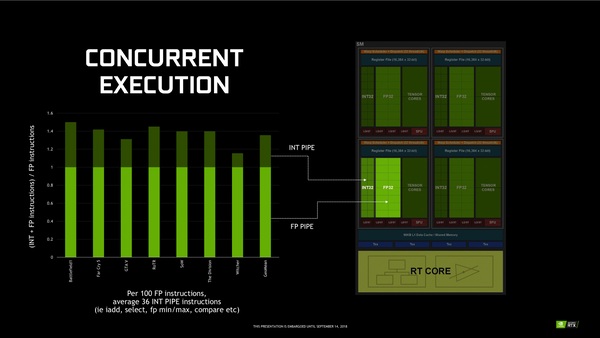
FP32とINT32の演算機を分けることで、2種類の演算を並列処理できるようになる。上の図は各PCゲームタイトルにおいて、FP32処理の割合を1とした時、INT32の処理がどれだけあるかを示したもの。グラフ中の濃い緑の部分がFP32と並列処理できるようになることで得られるメリット。
Turing世代ではキャッシュの階層にも大きな手が入った。PascalではSM内にL1キャッシュ48KB、それとは別に96KBの共有メモリー、そしてGPU全体で共有する3MBのL2キャッシュという構造を採用していた。これに対しTuringでは、SM内にL1キャッシュ兼共有メモリーが96KB、そしてGPU全体で共有する6MBのL2キャッシュという構成になった。
この新しい共有メモリーでは、L1キャッシュを最大64KBまで拡大できるので、L1キャッシュへのヒット率が高まる。また、L1キャッシュのレイテンシーを低減、さらにSM内のロード&ストアユニットへの帯域も従来より太くなっている。ゲームエンジンの設計にもよるが、このL1キャッシュの変更はパフォーマンスに大きく寄与する、とNVIDIAは謳っている。
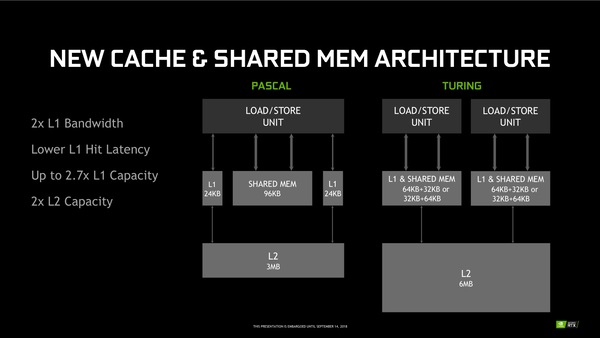
Pascal世代とTuring世代のキャッシュ構造の違い。TuringではL2が倍増したほかに、L1キャッシュと共有メモリーが合体した新しい共有メモリーを採用。分量は柔軟な可変式なのかモード切り替え式なのか明言されていないが、典型的なゲームの処理ではL1を64KB、共有メモリーを32KBにする処理が多く、コンピュートタスクでは逆にL1を32KBに絞って共有メモリーを64KBで使うことが多いという。
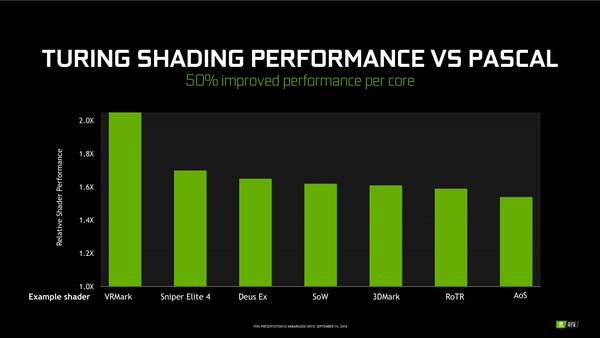
L1キャッシュと共有メモリーの合体により、特にL1キャッシュのスループットが向上し、レイテンシーは低減。ゲーム側の処理にもよるが、実ゲームでシェーダーの性能がおよそ1.6倍に伸びる(VRMarkなら2倍強)と謳っている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")


