
本連載は、Adobe Acrobat DCを使いこなすための使い方やTIPSを紹介する。第7回は、スキャンしたデータのPDFを文字検索可能にしてみる。
前回(第6回 紙資料をスキャンしてPDFファイルを作成してみる)では、紙資料をスキャンしてPDFファイルにする方法を紹介した。しかし、この状態では画像データのままなので、人の目で読むことはできるが、キーワード検索することはできない。
「Adobe Acrobat DC」なら、このPDFファイルにOCR機能を使い、画像から文字を認識させてテキストを埋め込むことができる。すると、オフィス文書から作成したPDFファイルのようにキーワード検索ができるようになるのだ。
まずは、既存のPDFファイルをスキャン可能にしてみよう。「スキャン補正」を開き、「テキスト認識」→「このファイル内」を選択すると、第2ツールバーが開く。ここにある「テキスト認識」をクリックすると、OCRが実行される。
OCRが完了すると、画像データの上に見えないテキストデータが埋め込まれる。これでキーワード検索ができるようになる。試しに、Ctrl+Fキーを押して文字を検索してみよう。該当箇所が反転し、検索できていることがわかる。

スキャンした紙資料のPDFを開き「スキャン補正」をクリックする
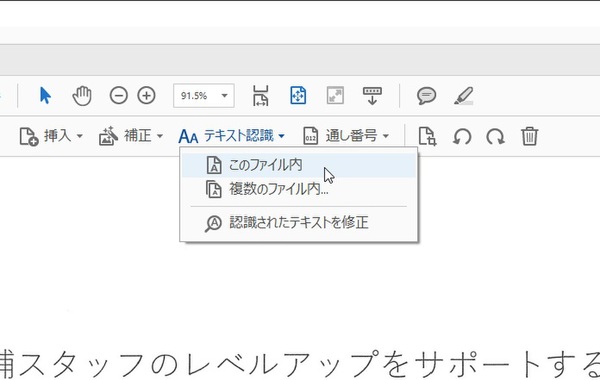
「テキスト認識」をクリックし、「このファイル内」をクリックする
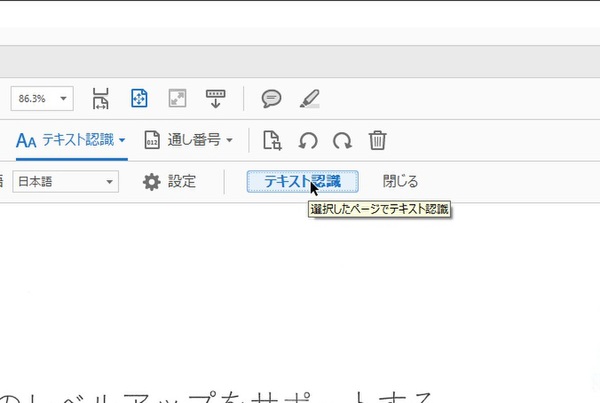
「テキスト認識」をクリックすれば認識開始。ページなどを指定するなら「設定」をクリック
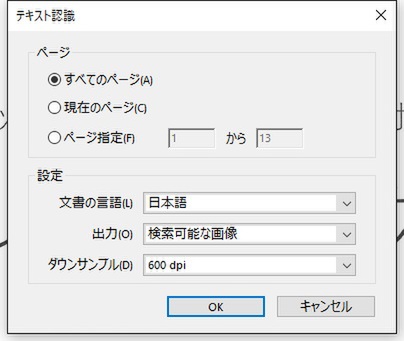
OCR処理するページや言語、ダウンサンプルの解像度などを指定できる
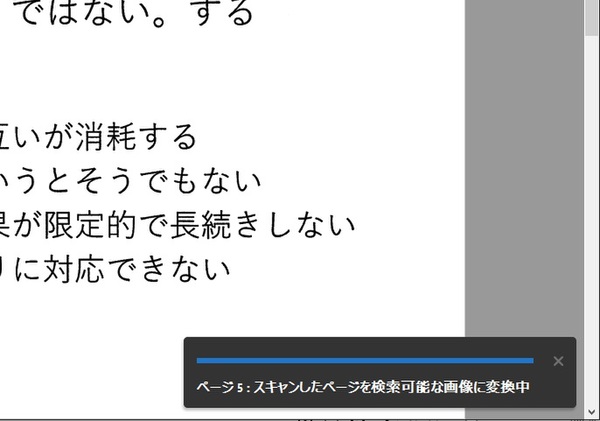
OCR処理は少し時間がかかる

OCR処理が完了。キーワード検索できるようになった
OCR処理でエラーが起きていると思われる部分があると、第2ツールバーに「認識されたテキストを修正」というボタンが現れる。ここで、認識できなかった部分を確認し、修正したり「同意する」をクリックする。この時、「認識されたテキストをレビュー」のチェックをオンにすると、画像の上に認識したテキストが重ねて表示される。
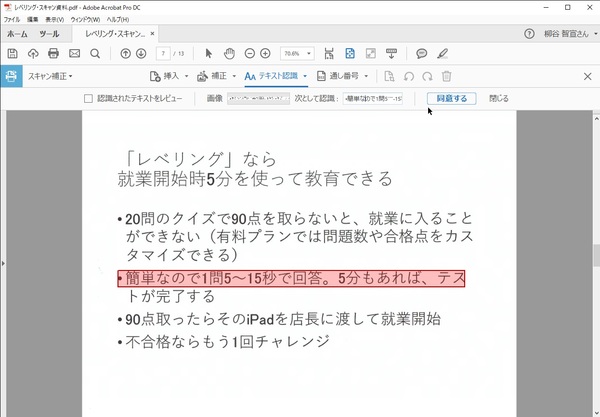
エラーの可能性がある部分をチェック。今回は「・」がなぜか認識されなかった
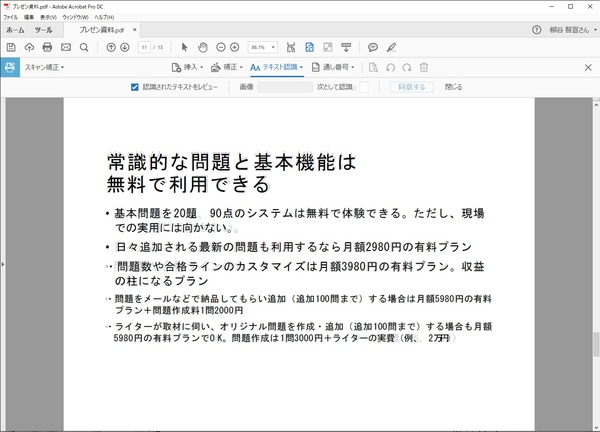
「認識されたテキストをレビュー」をオンにすると、元の画像の上に、埋め込まれたテキストが重ねて表示される。ばっちり認識されていることがわかる
実は、スキャンしてPDFファイルを作成するときに、同時にOCR処理を実行することもできる。今後スキャンする際は、この機能をオンにしておくと手間が省ける。
初期設定では、「検索可能な画像」として出力される。元の画像はそのままに、透明なテキストデータが埋め込まれるのだ。必要に応じて、画像の歪みなどが補正され、ダウンサンプルされてサイズをコンパクトにしてくれる。「設定」では、そのほかに「検索可能な画像(非圧縮)」や「編集可能なテキストと画像」という項目も選べる。「検索可能な画像(非圧縮)」は画像をそのまま維持する設定。「編集可能なテキストと画像」はページの背景を利用しつつ、元の画像と似ているフォントを合成してくれる。見た目は微妙に変わるものの、オフィス文書から生成したPDFファイルのように普通にテキスト編集できるようになるのがメリットだ。
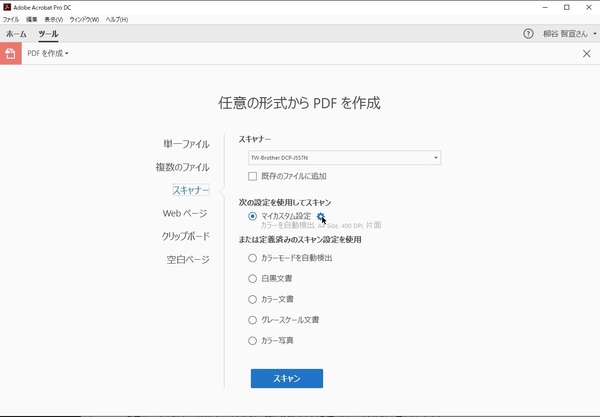
「PDFを作成」の「スキャナー」から設定アイコンをクリックする
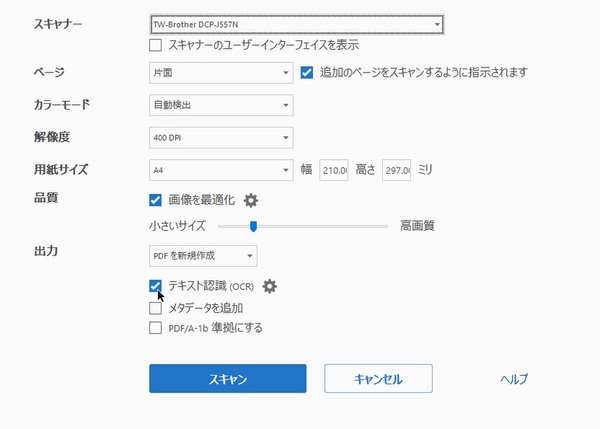
「出力」の「テキスト認識」にチェックする
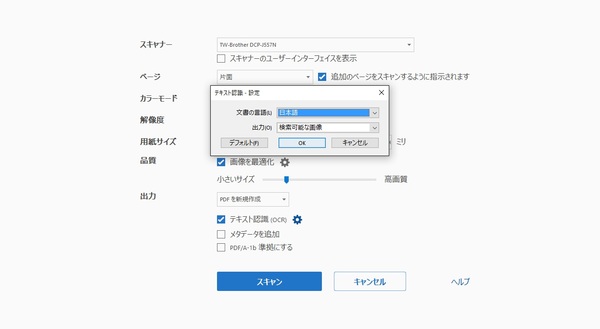
テキスト認識の「設定」では言語や出力方法を選べる
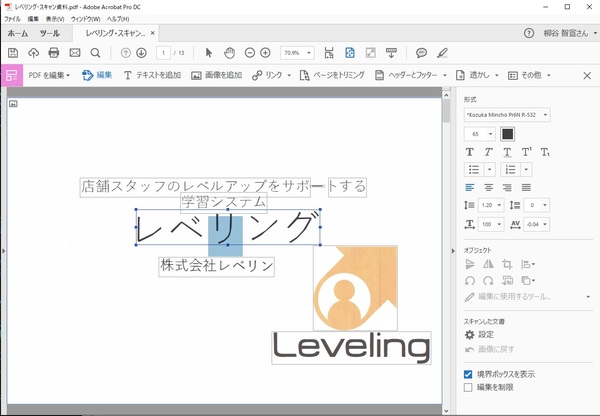
「編集可能なテキストと画像」でOCR処理したファイルは編集が可能になる
時々、OCR処理をして検索したのにヒットしないことがある。「認識されたテキストをレビュー」にチェックすればわかるが、時々日本語が認識されていないところがある。きちんとスキャンしていて、上記のような手順でOCR処理を実行しても解消されない場合はどうしようもないのであきらめるしかない。
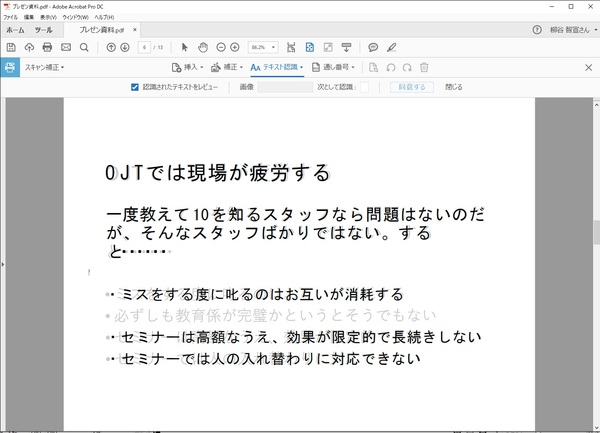
一部分の認識ができないこともある
この連載の記事
-
第167回
sponsored
ChatGPTからPDFの編集・統合・変換ができる! 無料アカウントで利用可能! -
第166回
sponsored
Acrobat AI アシスタントで難解な契約書をスッキリ理解する方法 -
第165回
sponsored
PDFからキーワードをサクッと検索 「簡易検索」と「高度な検索」を使いこなそう -
第164回
sponsored
リリースや証明書発行時に便利! 企業(組織)の角印に当たる署名をAcrobatで押す方法 -
第163回
sponsored
フリーランス法に対応! 「契約書メーカー」で作成した契約書にAcrobatで電子サインしてもらう方法 -
第162回
sponsored
PDFを印刷するため、PDF/X-4フォーマットで作成する作法 -
第161回
sponsored
Wordに書き戻しもできる! 意外と高機能な「コメント」をマスターしよう -
第160回
sponsored
共有前にPDFファイルサイズを圧縮してサイズをコンパクトにする方法 -
第159回
sponsored
図の代替テキストや読み上げ順序を設定してアクセシブルなPDFを作成する -
第158回
sponsored
あなたの会社が公開しているPDFファイル、アクセシビリティに対応していますか? -
第157回
sponsored
ページ数の多い資料にしおりを挟んで手軽にジャンプできるようにしてみる - この連載の一覧へ








