



クラスタ処理で数千万サンプル級の予測モデル生成を高速化「分散版異種混合学習技術」
NECが「高い精度と説明力」を備える独自の機械学習技術を強化
2016年05月27日 07時00分更新

NECは5月26日、2012年に発表した同社独自の機械学習技術を強化し、数千万サンプル級の超大規模データを用いた学習を大幅に高速化する「分散版異種混合学習技術」を発表した。同社が注力する社会ソリューション事業での活用も期待される技術。2017年度のサービス実用化を目指す。
同日の発表会では、4月に発足したNEC データサイエンス研究所から所長の山田昭雄氏、同技術の開発を牽引する主席研究員の藤巻遼平氏が登壇し、技術背景や具体的なニーズ、適用ソリューション領域などを説明した。

NEC データサイエンス研究所 所長の山田昭雄氏

NEC データサイエンス研究所 主席研究員の藤巻遼平氏
「高精度」と「説明力」を兼ね備えるNECの異種混合学習技術とは
NECが開発し、2012年に発表した「異種混合学習技術」は、通常の機械学習技術ではカバーできないような、複雑な「条件」が影響を与える事象に対し、データサイエンティストの人手を借りることなく分析モデルを自動生成し、将来予測を可能にする技術だ。
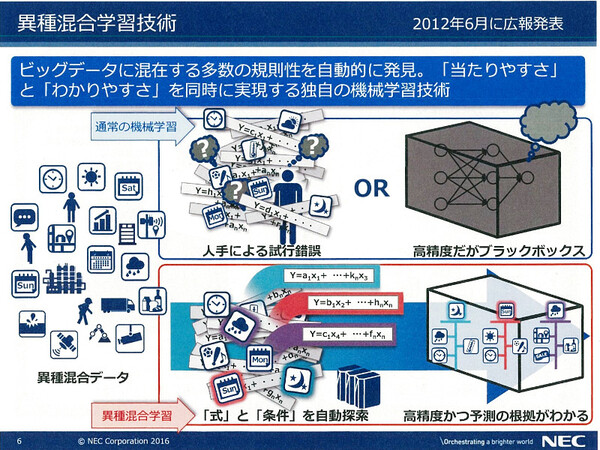
通常の機械学習(上左)やディープラーニング(上右)と、異種混合学習(下)との違い
藤巻氏は、「異種混合学習技術は『高い予測精度』と『(予測根拠の)説明力』を兼ね備えており、実用化も進み始めている」と説明する。現実世界は予測に影響する「条件」が複雑に入り組んでおり、通常の機械学習技術では予測の正確性に限界があること、異種混合学習技術ではその課題をクリアできるという。
「たとえば生活習慣病リスクの予測モデルを作る場合、現実には性別や年齢、身長などの『条件』によって、それぞれ異なるリスク要因(因子)が結果に影響を及ぼす。異種混合学習では、条件とリスク要因の組み合わせパターンまで自動探索できるので、『男性で身長が170センチの場合……』といった条件下での予測がより正確になる」(藤巻氏)
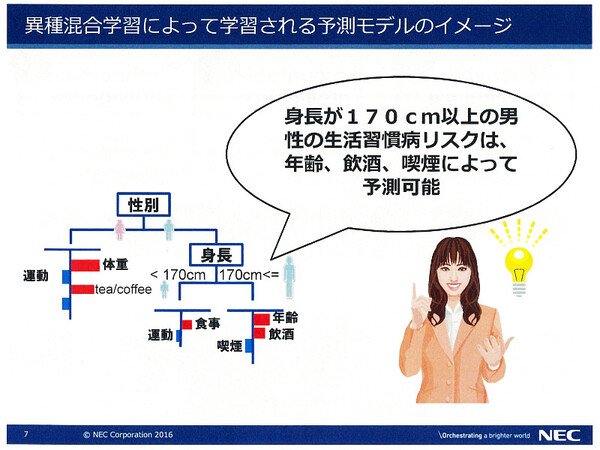
異種混合学習技術による予測モデルのイメージ。性別、身長といった「条件」までデータから自動探索し、モデルを生成するため、より正確な予測が可能になる
他方、ディープラーニング技術を使えば高精度な予測は実現可能だ。しかし、その「根拠(予測モデル)」が、人間には理解できないブラックボックスになってしまう。
そのため、ディープラーニングは「画像認識や株式売買といった、予測結果だけを重視する用途には向いている」(藤巻氏)ものの、社会インフラや医療、企業ビジネスなど重大な判断と説明が求められる領域には向いておらず、こうした領域では異種混合学習技術に優位性があるという。
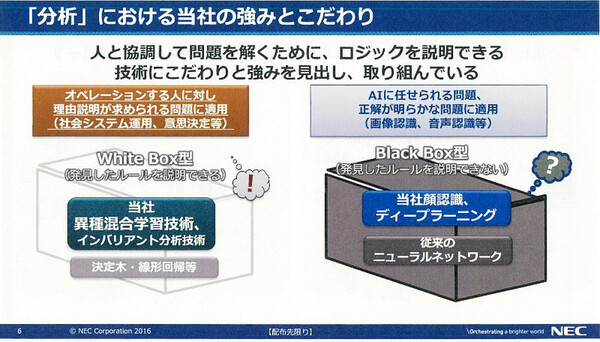
ディープラーニングは「なぜその予測結果なのか」が人間には理解できないブラックボックスになってしまう
すでにNECでは、この異種混合学習技術を顧客向けソリューションとして実用化しており、たとえばビルの電力需要予測、小売店舗における商材需要予測など、グローバルで幅広い活用実績がある。
「このように『高い精度』と『説明力』を兼ね備える異種混合学習は、さまざまな分野での予測ソリューションとして実用化が進んでいる。顧客も現実にそこからビジネス価値を得始めている」(藤巻氏)

同技術を採用した予測ソリューション例。グローバルで実績があるという
従来技術の課題を分散クラスタで解決する「分散版異種混合学習技術」
さて、こうして異種混合学習技術がソリューションとしての実績を積む中で、より大規模なデータを予測に使いたいというニーズが出てきた。「たとえば、これまで一店舗のデータだけでやっていた小売業の販売予測を、全店舗のデータを使ってやりたいと。その予測モデルを使えば、まだデータの溜まっていない新規店舗での販売予測も可能になる」(藤巻氏)。また今後、IoTデバイスからの情報収集が一般的になれば、大量のデータ処理が必要になるシーンはさらに増える。
しかし、従来の異種混合学習技術では、数千万件クラスの大規模サンプルを取り扱えないという課題があった。単一ノード構成のアーキテクチャであるため、「大規模データを丸ごとメモリに取り込むことができない」、あるいは「CPUパワーの制約で非常に長い処理時間がかかってしまう」といった課題だ。
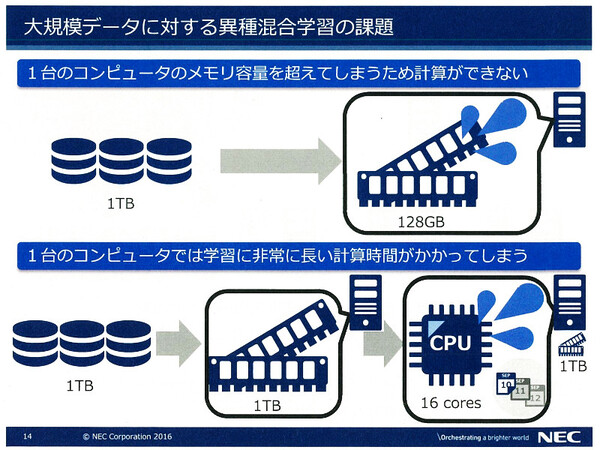
従来の異種混合学習技術では、大規模なデータを扱ううえで課題があった
そこでNECでは、同学習技術がクラスタ上で稼働するようアルゴリズムを新規開発し、分散計算基盤である「Apache Spark」上で動作するエンジンとして実現した。これが、今回発表された「分散版異種混合学習技術」である。
分散版異種混合学習のクラスタは、1台の「driver」ノードと複数台の「executor」ノードで構成される。driverノードが全体の“監督役”であり、異種混合学習技術を用いて予測モデルを作る学習処理は各executorが個別に行う。それぞれのexecutorは、大規模データの“一部分”だけ(メモリに格納できるサイズのデータ)を保持している。

分散版異種混合学習の特徴。driverノードと複数台のexecutorノードで構成される
ここからが同分散技術のキモだ。この構成で各executorノードが学習処理を行うと、それぞれが持つデータに応じた異なる予測モデルが生成される。ただし、この予測モデルは、ほかのexecutorノードが持つデータに適合するとは限らない。そこで、driverノードは各executorノードから予測モデルを収集、統合し、その予測モデルをexecutorノードに配布する。executorノードは再度、各自の持つデータでこの予測モデルで学習処理を行う(予測モデルを補正する)。
driver-executor間でこの処理を繰り返すことで、各executorノードがデータの一部分だけしか持っていなくとも、予測モデルは大規模データの「全体」に対して最適化されていく。ノード間でやり取りされるのはサイズの小さな予測モデルのデータだけなので、単純にexecutorノードの台数を増やしていくだけで、データ規模の拡大やパフォーマンスの向上ができる。
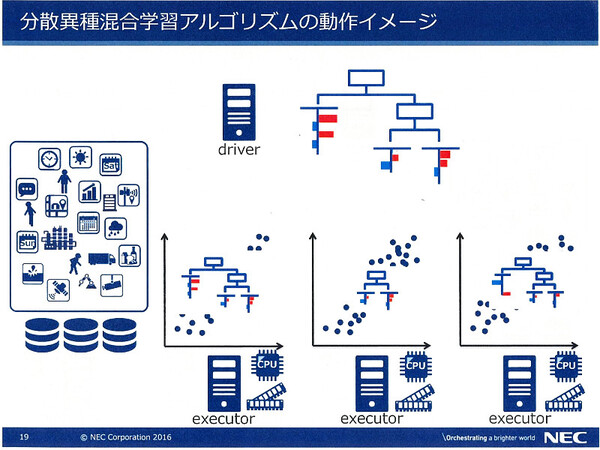
各executorノード(下)は局所的なデータしか持っていないため、大規模データ全体に適合する予測モデルを生成できない。そこでdriverノード(上)がそれを統合し、配布するする。これを繰り返すことで予測モデルが最適化される
NECでは、全国のATM約2万台から収集したデータを使用して、分散版異種混合学習(10ノード)と従来の異種混合学習(1ノード)との比較実験を行った。その結果、約2300万件のサンプルから学習したケースでは予測精度が17%向上した。また異種混合学習ノードのメモリサイズに合わせて1000万件のサンプルに絞ったケースでは、学習速度が約110倍向上したという。「1~2週間かかっていた学習が、2~3時間で済むようになったということ」(藤巻氏)
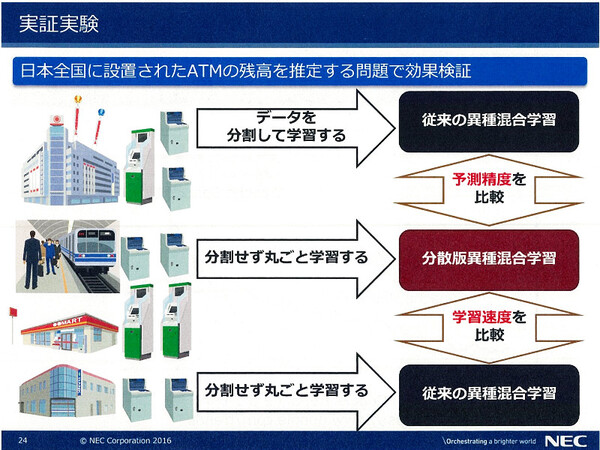

予測精度、処理速度を比較する2種類の実証実験を実施。分散版技術の優位性が明らかになっている
本記事はアフィリエイトプログラムによる収益を得ている場合があります









の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





