




NECは8月18日、ビッグデータの予測分析における事前のデータ処理を行うための新技術を開発した。予測に役立つ特徴的なデータ(以下、特徴量)の生成と、その評価を自動化する「特徴量自動設計技術」として、2015年度中の実用化をめざす。
ビッグデータに対して高精度な予測分析を行うためには、対象データが分析に大きな影響を及ぼす条件を発見し、条件に当てはまる特徴点の生成手順を設計するとともに、データの生成・評価を行い、これら一連のプロセスを繰り返す必要があるという。
その設計には高度なデータ相関分析や、人手による実験・検証が必要なため、これまで専門ノウハウを持つデータ分析技術者が手動で設計していた。
新技術は、NECが開発したビッグデータに混在する多数の規則性を発見する「異種混合学習技術」による分析を行う前に、特徴量の生成に関する一連のプロセスを自動化するもの。分析期間の大幅な短縮に寄与する。
新技術の特長
具体的には、データ変換の組み合わせを高速に探索できるアルゴリズムを開発。分析対象となる大量のデータに対して、「データ変換処理」の膨大な組み合わせの中から、最も適切な組み合わせを高速に探索し、データ分析に有効な特徴量を自動的に算出する。
また、特徴量の算出において、「標準化」「移動平均(時系列データの平準化)」など、データ分析技術者がこれまで多くの経験で培った様々な「データ変換処理」をライブラリ化した。同ライブラリを組み合わせて、多様な特徴量を簡単に生成できるという。
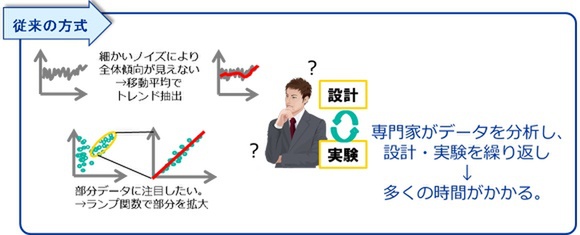
従来の方式では、専門家による手動の作業が発生し、多くの時間がかかる
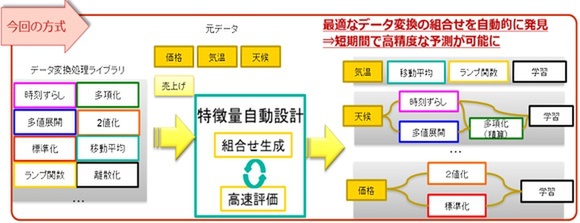
新技術では、最低なデータ変換の組み合わせを自動的に発見できる
本記事はアフィリエイトプログラムによる収益を得ている場合があります






ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
