




スーパーコンピューターの系譜では、主にアメリカのシステムを取り上げており、そこに時々イギリスが混じる(前回のMeikoなど)といった具合だが、この時期米英だけがスパコンに取り組んでいたわけではなく、日本もまた積極的に参加していた。
このあたりの話、概略はWikipediaなどを見ていただければわかるかと思う。この話を真面目に書くとそれだけで連載何本分かになるので、とりあえず今回は触れないでおく。
もちろん他の国がなかったわけではなく、ヨーロッパでもいくつかの試みがなされていた。今回ご紹介するのはそのうちの1つ、ドイツのSUPRENUMである。

SUPRENUM-1
SUPRENUM、ドイツ語での正式名称はSUPerREchner fur NUMerische Anwendungen、英語ではSuper-Computer for Numerical Applicationsだが、ドイツ語表記の短縮形がSUPRENUMになり、これで一般的に通用する。これはドイツの産学協同プロジェクトとして1986年にスタートした。ちなみに参加団体は以下のとおり。
| 研究機関 |
|---|
| GMD(ドイツ国立情報処理研究所 現フラウンホーファー研究機構)傘下の2つの研究施設 KfA(ユーリッヒ原子力研究所 現ユーリッヒ研究センター) KfK(カールスルーエ原子力研究所 現カールスルーエ研究センター) DLR(ドイツ航空宇宙センター) |
| 大学 |
| ダルムシュタット工科大学 ライン・フリードリヒ・ヴィルヘルム大学ボン(ボン大学) ブラウンシュヴァイク工科大学 ハインリッヒ・ハイネ大学 フリードリヒ・アレクサンダー大学エアランゲン=ニュルンベルク |
| 企業 |
| シーメンス社KWU ドルニエ航空機製造(現フェアチャイルド) Krupp Atlas Elektronik GmbH(現Atlas Elektronik GmbH) Stollmann GmbH(現Stollmann Entwicklungs- und Vertriebs GmbH) |
これにSuprenum GmbHが加わった。SUPRENUM GmbHは名前の通り、SUPRENUMを製造・販売する目的で設立された会社であり、まずはPhase-1としてSUPRENUM-1の製造に取りかかった。
MIMDのプロセッサーにSIMDのベクトル処理能力を加えた
SUPRENUM-1
SUPRENUM-1はMIMDベースの超並列構成のシステムを目指して構築されることになった。もっとも単純なMIMDというよりもMIMD+ベクトルという、おそろしく重厚なシステムである。
SUPRENUM GmbHのKarl Solchenbach氏が1990年に発表した“SUPRENUM: Architecture and Applications”という論文によれば、コスト性能比を高めるためにSUPRENUMはMIMDの分散メモリー方式のプロセッサーにSIMDのベクトル処理能力を加えたもの、という説明がなされている。
論文は以下のとおり。「100MFLOPSの演算性能を実現する、もっともコスト効率の良いメカニズムはベクトルである。一方スーパーコンピューターをターゲットとしたMIMDのマルチプロセッサーは、単純なFPUユニットを利用してベクトルと同じ性能を得ようとしている」
「それゆえ、パラレリズムを2つのレベルに分け、ローカルではベクトルプロセシング、グローバルでは細粒度のMIMDを構成するSIMD/MIMDのミックスなマルチプロセッサーが一番パワフルなアーキテクチャーとなる」という。いや、それはそうなんだけど……という話である。
その話は後にして、SUPRENUM-1の中身はどんな感じかというと、下の画像がシステム全景である。16個のコンピューティングクラスターが2次元トーラスで総合接続され、次いでにUnixゲートウェイと接続される仕組みだ。各々のトーラスリング(SUPRENUM-busという名称だそうだ)は200Mbpsの速度となっている。
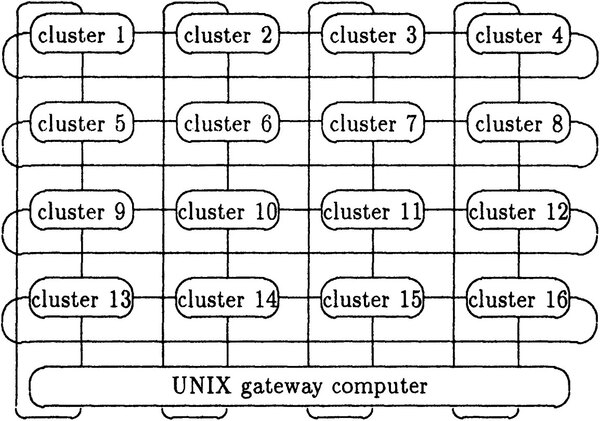
SUPRENUM-1のシステム概要。OSそのものはUnixゲートウェイの外側で動作するので、SUPERNUMのクラスター/ノードは完全なアクセラレーターとしての動作になる
画像の出典はKarl Solchenbach氏の“SUPRENUM: Architecture and Applications”より。
コンピューティングクラスターの中身は、下の画像のように、320MB/秒のクラスターバスという、おそらく共有バスの上に16個のノード+αが接続された形である。
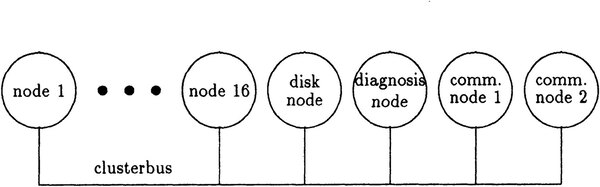
disk nodeには最大で4台、4.8GBのHDDが接続されたそうだ。comm.nodeはSUPERNUM busのI/Fで、縦方向と横方向のそれぞれに1つづつ用意された
画像の出典はKarl Solchenbach氏の“SUPRENUM: Architecture and Applications”より。
このクラスターバスの実体がなにかはよくわからないのだが、時期や速度を考えると、VMEないしFutureBusの独自拡張版だったのではないかという気がする。
時期的にはVME320はもとよりFutureBus+ですら間に合わないが、VMEのままでは性能はピークで40MB/秒程度でしかない。ただ、後述するようにカードとコネクターは明らかにVMEのようなので、おそらく信号線の増強などで独自にバス幅や信号速度を増やして対応したものと思われる。
(→次ページヘ続く 「20本のキャビネットが並ぶ巨大なシステム」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































