



REDEFINEは成功したか?EMC WORLD 2014レポート 第5回
Data Lakeは保存ではなく、プロセス課金のモデルへ
とことんオープン!Cloud Foundry戦略をマリッツCEOが語る
2014年05月09日 06時00分更新

Data Lakeはプロセスノードごとの課金へ
クラウドOSの上位に位置するミドルウェア層が「Data Lake」になる。Data Lakeが目指すのは、すべてのデータの置き場所として機能するデータプールだ。しかも単に置き場所という役割だけではなく、その場で分析まで実現する。基幹系DBからバッチでデータをDWHに転送し、分析を行なうという現在のアプローチとは考え方が根本的に異なるわけだ。
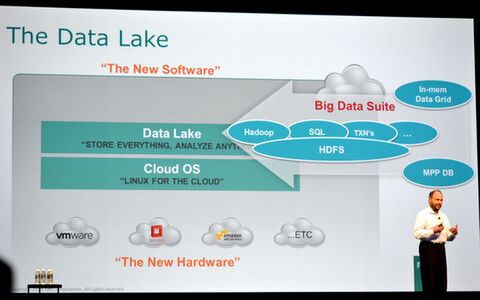
共通のデータプールを、さまざまな用途で利用できる「Data Lake」のコンセプト
PivotalはこのData Lakeを実現するために構築しているのが「Big Data Suite」だ。Big Data Suiteは、HadoopのファイルシステムであるHDFSをベースにしつつ、Greenplumの超並列DBとGemFireのインメモリDBの技術を組み合わせたデータストア。「将来のデータファブリックというのは、共通のストレージレイヤーを活用し、並列化の技術ではなく、いくつものマッチングモデルを使えるものだ。データファブリックが変われば、業界が変わるだろう」(マリッツ氏)とのことで、1つのデータストアをSQLやクエリ、トランザクション、コンプレックスイベントなどで並列的に利用できる。
今回明らかにされたのは、課金モデルの変更だ。Data Lakeの概念は、とにかくすべてのデータを同じ場所に保存すること。しかし、保存に対して料金が発生すると、実際に利用価値があるかどうかわからないデータは、捨ててしまうことになる。これに対して、マリッツ氏は「これからは支払いをプロセスノードごとに変える。データをメモリに載せ、処理を開始したところから課金しようと考えている」と述べ、保存ではなく、分析に対してチャージするモデルに移行することを明言した。
その後、マリッツ氏は、Data Lake上に載るアジャイル型の開発環境やEMC、VMwareとの連携について説明。実際のアプリケーションのデモを披露し、IoTなどを見据えた新世代アプリケーションの可能性をアピールした。既存のエンタープライズITベンダーとは異なる戦い方で、クラウドプレイヤーに勝とうというPivotalの方向性が鮮明に打ち出された講演だった。
この連載の記事
-
第6回
サーバー・ストレージ
EMC WORLDの展示会場に学ぶ米国流ITイベントの作り方 -
第4回
サーバー・ストレージ
Hotel California型クラウドに疑問を投げかけるゲルシンガーCEO -
第3回
サーバー・ストレージ
EMCトゥッチ会長、第3のプラットフォームへの意気込みを語る -
第2回
サーバー・ストレージ
謎のフラッシュベンダーDSSDをEMCが買収した狙いとは? -
第1回
サーバー・ストレージ
コモディティハードやOpenStack対応で裾野を拡げたViPR 2.0 -
サーバー・ストレージ
REDEFINEは成功したか?EMC WORLD 2014レポート - この連載の一覧へ




