



COBOL時代を知るPivotal APAC CTOが語る“第3のプラットフォーム”
クラウドロックインさせない「Pivotal One」のインパクトとは?
2013年12月13日 06時00分更新

12月12日、Pivotalジャパンは「Pivotalジャパン サミット 2013」を開催した。VMwareとEMCのエンジニアと製品群を集結させ、ビッグデータやクラウドを前提とした第3のプラットフォームを構築しようという意欲的な試みの全体像と今後の方向性が説明された。
Webジャイアンツの革新的なシステムを企業でも
Pivotalジャパン サミット 2013で登壇した米Pivotal アジア・パシフィック・ジャパン CTOのスティーブ・イリングウォース(Steve Ilingworth)氏は、Pivotalの展望と戦略と題したパワフルな講演を行なった。

米Pivotal アジア・パシフィック・ジャパン CTO スティーブ・イリングウォース氏
古くはCOBOLのプログラマーだったというイリングウォース氏は、第1世代のメインフレーム時代から第2世代のクライアント/サーバー時代の変化を目の当たりにしてきた経験を語る。「ハードウェア、OS、ソフトウェア、データベースなど、とにかくすべてのテクノロジーが変わった。しかし、このクライアント/サーバーの時代は、すでに40年近く続いている」(イリングウォース氏)。
そして、第3世代となるクラウド時代への移行は、クライアント/サーバー時代への移行と同じ、もしくはそれ以上のインパクトを持つと指摘した。イリングフォース氏は「第3世代の移行は、単にテクノロジーがかっこいいから起こったわけではない。企業はITにコストを払わなければならないからだ。その点、第3世代のクラウド時代ではCPUやメモリ、ストレージを無料で使える。ソフトウェア開発も第2世代ではハードウェア調達やソフトウェアのインストール、設定などで、数ヶ月かかったが、第3世代では数分で開発を始められる」と語る。

第3世代となるクラウド時代へ
こうしたITの新潮流を牽引するのが、GoogleやFacebook、Amazon、Yahoo!などのいわゆる“Webジャイアンツ”だ。イリングウォース氏は「たとえば彼らは最初から紙を成果物を作らないので、ドキュメントという概念がない。Googleは毎秒恐ろしい量のデータに対して瞬時にクエリをかけているし、Facebookは毎日のようにアプリケーションを更新している」といった例を挙げ、第2世代とはテクノロジーだけではなく、ユーザー体験も、ビジネスモデルも、ビジネスの価値さえも根本的に違っていると説明する。
そして大きな相違点はビッグデータだ。「ビッグデータは別に新しい概念ではない。ほとんどの企業はすでにビッグデータを持っている。Webジャイアンツたちが違うのは、このビッグデータを“使っている”ことだ。データを分析することで次を推測し、顧客を理解し、レコメンデーションを行なっている」(イリングフォース氏)。しかも、最初に数万にしか過ぎなかったユーザーが10億にまで拡大し、クラウドを活用することで、システムもスケールさせている。イリングフォース氏は、これを実現するために、ソフトウェア開発、データの収集、分析という3つのプロセスを融合し、1つのサイクルで連動させている点が大きいと指摘した。
クラウドロックインさせないPivotal One
しかし、一般企業がクラウドを用いて、Webジャイアンツのようなビッグデータ分析をしようと思うと、クラウドサービスによるロックインの影響を受けるという。「好きなクラウドで運用したいのに、アプリケーションを動かせない。これではメインフレーム時代に逆戻りだ」(イリングフォース氏)。
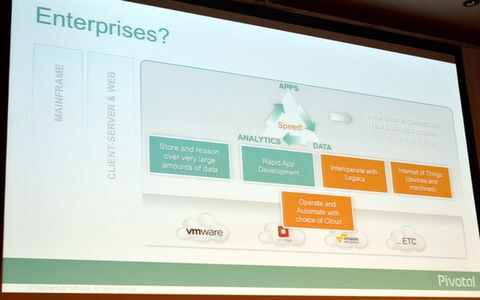
クラウドのロックインを排除する必要がある
これを排除するのが、Pivotal Oneだ。Pivotal Oneは特定のクラウドに依存しないクラウドファブリックであるCloud Foundryベースの新しいクラウドOS上に、Springフレームワークベースの新しいミドルウェアと、構造/非構造化データに対応する新しいデータファブリックを構築し、これらをプラットフォームとして提供している。VMwareやEMCの技術者が心血を注いで開発したPivotal Oneは、2013年の11月12日にめでたくGA(General Availability)になった。
ビッグデータのキモになるデータファブリックには特に注力したという。巨大なコンピューターでRDBMSを振り回していた従来のアプローチを用いずとも、Googleが検索とインデクシングに用いたHadoopとMapReduceを使うことで、大容量のデータを短時間に処理できるようになった。「今、Hadoopの可能性を理解しなければ、5年後に大きく後悔することになる。将来性が100%保証できるものだ」と、イリングフォース氏は高く評価。その上で、Hadoopの使いにくい部分を商用ソフトとしてカバーしたのが、Pivotalのデータファブリックプラットフォームだ。
Pivotal Oneのデータファブリックでは、HadoopのHDFSで共通データ基盤を構築。「孤立した“データの島"ではなく、HDFSですべてのデータを“データの湖(Data Lake)”に保存する」(イリングフォース氏)。その上で、独自のMapReduce実装である「Pivotal HD」、超並列型リレーショナルDBである「HAWQ」、インメモリサービスの「GemFire XD」などを取りそろえ、HDFS基盤の構造化/非構造化、ストリーミング/トランザクションなどのあらゆるデータを扱えるようにした。
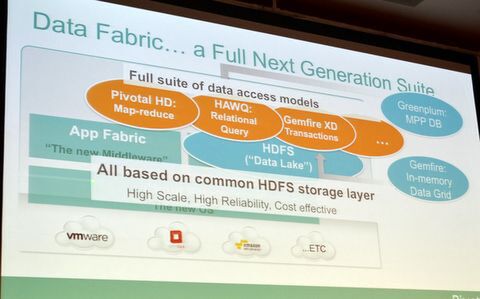
あらゆるデータタイプをHDFSの基盤で取り扱えるPivotal Oneのデータファブリック
Pivotal Oneを構成するコンポーネントの導入も含め、Pivotal製品は数多くのビッグデータ事例で用いられている。たとえば、アジアのある都市では、渋滞を減らすための交通制御のためにPivotal製品が用いられている。また、中国の鉄道会社では座席予約システムに、イギリスの通信事業者ではネットワークの通信制御に、そしてインドでは12億人の生体IDの管理に用いられているとのこと。
しかし、ビッグデータの活用には、製品だけでは不十分だという。イリングフォース氏は「Pivotal Oneはパワフルな製品だが、企業がビッグデータを活用するにはデータサイエンティストや新しいソフトウェアのサポートが必要だ」と述べ、人材育成や開発支援をグループ全体で進めていくと説明した。




