



シンプロビジョニングや自動階層化などを解説
サーバーの次に注目されるストレージの仮想化
2011年07月28日 09時00分更新

ストレージの仮想化技術
ストレージの世界では、サーバーよりも早い段階で仮想化技術が実用化されていた。たとえば、ディスクアレイ/RAIDも仮想化技術の一種であり、小容量のHDDを多数組み合わせて全体を仮想化することで巨大なボリュームを作っていると見ることもできる。
一方、現代的な仮想化技術としては、複数のストレージシステムを仮想化して統合することで全体を巨大な仮想ボリュームにする技術も実用化されている。市場では数種類の実装が混在している。仮想化機能を実装したメインのストレージデバイスの配下に他のストレージを接続し、メインのストレージの容量が拡大したように見せるものもあれば、仮想化機能だけを担う仮想化アプライアンスを利用して、配下のストレージデバイスの容量を統合する手法や、サーバ上のソフトウェアで仮想的な巨大ボリュームを実現するものもある。こうした仮想化に関しては、主にSANストレージでの利用が主となる。
シンプロビジョニング
現在のサーバー仮想化で主流である、1つのリソースを複数の仮想リソースに分割する方向の仮想化に関しては、ストレージの世界では古くから「パーティショニング」という形で実現されているものだ。ただし、従来はいったん設定したパーティションサイズを後から任意に変更することはできず、柔軟性に乏しかったが、現在では「シンプロビジョニング」という形でこうした制約も回避可能になっている。
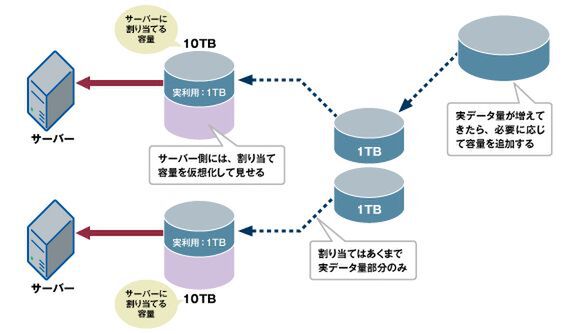
シンプロビジョニングの仕組み
シンプロビジョニングは、サーバー側には巨大なボリュームサイズを仮想的に見せておきつつ、実容量はデータサイズに応じて必要な分だけ確保しておく、という手法だ。たとえば、サーバー側から見ると10TBのボリュームに見えているが、実際のHDDは3TB分しかない、といった状況だ。ボリュームサイズを後から拡張するのは難しかったので、従来は将来必要になりそうな容量を見越してあらかじめ容量を確保しておく、という手法が一般的だった。最終的には確保された容量を使い切るところまでデータ量が増大することになるとしても、初期には確保された容量の一部しか使われておらず、無駄な空き容量が遊んでしまっているという状況になり、これがストレージの容量効率を低下させる一因となっていた。しかし、シンプロビジョニングによってデータ量の増加に応じて段階的に物理容量を拡大していくことが可能になり、投資効率を向上させることができるようになった。
利用頻度でデータを分類する自動階層化
このほか、最近注目を集めているとしては自動階層化がある。ストレージの階層化とは、アクセス速度と容量単価が異なる複数のストレージデバイスを組み合わせ、全体最適を実現するという考え方だ。サーバ側のテクノロジーと比較するなら、メモリシステムにおけるキャッシュの考え方とほぼ同様のアイデアである。
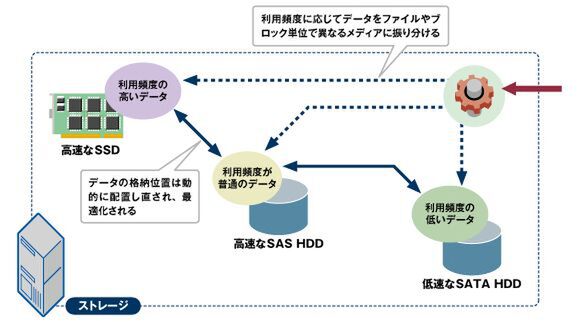
自動階層化の概念
かつての階層化は、アーカイブ用のテープライブラリと、旧型等の比較的低速なストレージデバイスと、最新の高速なストレージデバイスをデータの特性によって使い分けるという発想であり、階層移動の単位は主にファイルなどの論理的なまとまりであり、手動もしくはサーバ上で稼働するソフトウェアによる移動が想定されていた。一方、現在のエンタープライズストレージにおける自動階層化は、ストレージデバイスの筐体内にアクセス速度の異なる複数の記録メディアを混在させ、ストレージデバイス側が自動的にこれらのメディアを使い分ける、という段階まで進化している。
この技術が注目されるようになった背景には、高速な記録メディアとしてSSD(Solid State Disk:半導体ディスク)が実用段階に入ったことが挙げられる。SSDは従来のHDDに比べると低消費電力で、特にランダムな読み出しに際しては圧倒的な高速度を実現できるが、容量単価はHDDとは比較にならないほど高価なデバイスであり、大容量を実現するのは難しい。そこで、HDDに比べれば相対的なわずかな容量のSSDを効率よく活用するため、アクセス頻度が高いデータだけをSSDに格納する、といったキャッシュ的な利用が行なわれている。
自動階層化が実現した背景には、ブロックアドレスの仮想化技術がある。かつてのストレージでは、ブロックアドレスは記録メディア上の特定の物理位置を直接指し示すものだったが、仮想化によってこの直接的な対応関係はストレージ側で柔軟に変更できるものへと変わった。この結果、ストレージ側の自動階層化機能によってデータが記録される物理的な位置が変更されても、データにアクセスしてくるサーバー側にはその変更は隠蔽され、従来と何も変わらずにアクセスできることが保証される。
さらにいえば、シンプロビジョニングに関しても同様の仮想化が活用される。仮想的に確保された巨大ボリュームのどこに対してアクセスが発生しても、必ず物理的に実装されている記録メディアのどこかにアクセスが転送されるよう制御できて、初めてシンプロビジョニングも実装可能になるわけだ。
ストレージの仮想化は、デバイス単位からブロック単位まで、さまざまなレイヤで高度な進化を遂げており、より高機能かつ使いやすいストレージシステムを実現するための重要な基盤技術となりつつある。
データ量の削減を目指す重複排除
ストレージの進化は、いわば「より大容量に」「より高速に」という規模拡大の歴史でもある。しかし、IT投資の中に占めるストレージシステムのコストが増大し続けており、コスト削減を迫られるようになってきている。一方、データ量の爆発的な増大はさらにペースを速めつつあり、このペースに合わせてストレージの総容量を拡大し続けることは現実的ではなくなりつつあることも相まって、データ量の増加ペースを抑制する動きも出てきている。このための具体的な対策として洗練が進んでいるのが、データの重複排除技術だ。
ストレージに保存されるデータに重複が多いことは容易に想像できるだろう。重要なデータや変更の多いデータは、「念のため」といって手軽にコピーを作ることから、ストレージ全体を丹念に探すと同一ファイルのコピーが山ほど出てくるものだ。また、オフィスドキュメントなどでは、ちょっとした変更を加える際にオリジナルのファイルはそのまま残しておき、新たなコピーを作成してそちらを変更する、といった作業が一般的に行なわれているため、内容が微妙に異なる「バージョン違い」といったファイルが大量に残されていたりする。こうしたコピーは、データ破壊/データ喪失を避ける上で必要なものでもあるが、あまりに大量になると無駄にストレージ容量を圧迫する結果になる。
重複排除技術では、こうした同一もしくは類似のデータ/ファイルをストレージ内部で見つけ出し、それらを統合することで容量消費を抑制する機能だ。重複の検出単位は、ファイルまたはブロックが想定される。ファイル単位の重複排除では、同一内容のファイルのコピーを見つけ出し、1つを残して他はリンク/ショートカットという形で同じ実体を参照するようにする。ただし、この場合は1つのファイルに対する変更が全コピーに波及してしまうという副作用があり、バージョン違いをコピーとして残したいといった場合には困るので、重複排除後に行なわれた変更は個別に保存するなどの対策も併用する必要がある。
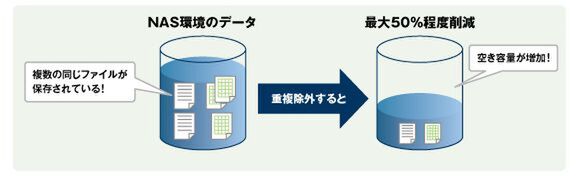
ストレージの重複排除
ブロック単位の重複排除は、データ/ファイルを構成しているデータブロックの中から共通する要素を見つけ出し、統合していくものだ。この場合、一部だけが変更されたバージョン違いのファイルなども共通部分を抜き出して統合できるなど、データ容量削減の効果はファイル単位での重複排除よりも大きくなることが期待されるが、処理はその分複雑になる。重複ブロックの発見を高速に行なうための技術としては、データをビット単位で比較するのではなく、ブロックごとにハッシュ値を求め、このハッシュ値に基づいて判断するなどの手法が使われる。
通常利用されているストレージの容量効率はあまり高くはなく、おおむね容量効率は3~4割程度な上、さらに重複データを排除することで使用容量が半分以下に削減できる例もあるという。このため、データの重複排除を導入することでストレージの新規追加/容量増加のタイミングを遅らせ、投資効果を高めることが可能になる。
一方、重複排除はデータの冗長性を削減する技術でもあるため、データ破壊/喪失のリスクに備えた適切なデータ保護やバックアップを併用することがますます重要になる。ストレージの記録メディア上に障害が発生してあるブロックが破損した場合、従来ならそのブロックを使用中の1つのファイルのみに影響が限定されていたわけだが、重複排除を利用している場合、複数のファイルに同時に影響が波及する可能性もある。単純な機械的な破壊に備えるために適切なRAIDレベルで運用する必要があるのはもちろん、バックアップの作成間隔なども充分に検討すべきだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第20回
サーバー・ストレージ
データ保護の技術 可用性を高める技術 -
第19回
データセンター
「i」に対応!IBMの「リモート・データ保護」が対象拡充 -
第19回
サーバー・ストレージ
バス変更などで性能4倍!日本IBMのストレージ「XIV Gen3」 -
第19回
サーバー・ストレージ
データを守るRAIDとストレージのネットワーク化 -
第17回
サーバー・ストレージ
自動階層化で効率化を追求したDell Compellent -
第17回
サーバー・ストレージ
ハードディスクと外付けディスクアレイ装置 -
第16回
サーバー・ストレージ
再評価されるテープライブラリの最高峰「HP ESL G3」 -
第15回
サーバー・ストレージ
日本SGI、最大1PBのストレージ「InfiniteStorage 5500」 -
第14回
サーバー・ストレージ
自動階層化とPowerShellに対応した新SANsymphony-V -
第13回
サーバー・ストレージ
クラウドの4要素は「NetApp OnCommand」で管理できる - この連載の一覧へ



