




限界を打破するハイブリッドボンディング
AIの進化を支えるHBM積層技術の新潮流
HBMといってもDRAMには違いないわけで、セルの構造の進化そのものはDRAMと違いはない。異なるのはパッケージ技術のみである。そのHBM、AIブームのおかげで猛烈な売り上げが立ち、かつどんどん高速化しているというのはご存知のとおり。
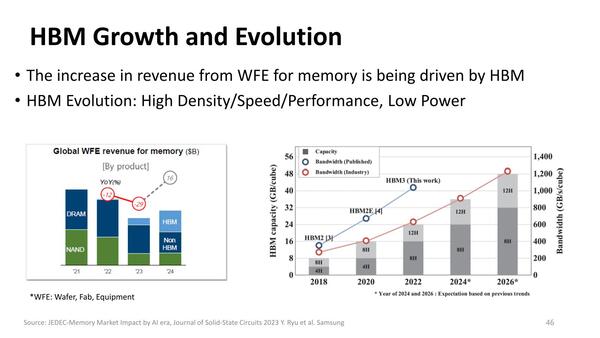
これは2023年のデータなので、右のグラフには"HBM3 (This work)"と書いてある。内容が古いのは仕方がない
問題となるのは、より高い帯域が求められていることと、もう1つは積層数が多すぎて高さがかなりのものになっていることだ。
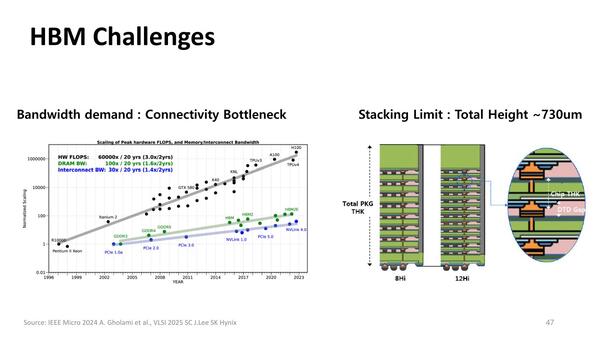
それぞれの基板をギリギリまで薄く削っても、基板同士の接続にBumpを使っているのでそこが厚みを減らせない最大の要因ではある
これは2つのデメリットがある。1つは高さがありすぎて、ASICの横に置くとASICの高さを超えてしまうこと。これは、ヒートスプレッダの工夫が必要になる。それともう1つ放熱の問題もある。HBMの場合、積層の一番下にASICとのI/Fのダイが入るが、この発熱を逃がすためには上に積みあがっているDRAMのダイを経由して放熱する必要があるのだが、層数が多くなると放熱効率が当然悪いことになる。
特にHBM3以降(3/3E/4/4E)では信号速度が高速化する分発熱量も多いので、これをなんとかしないと発熱を抑制する(=信号速度を低めに抑える)必要性が出てしまい、好ましくない。
ではどうするか? というと、従来のμBumpを使った接続方式から、Hybrid Bondingに切り替えるというやり方である。
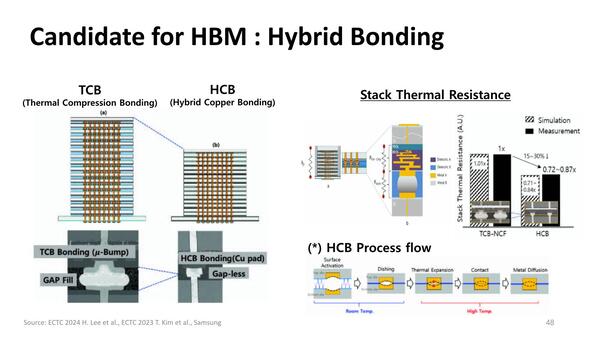
Hybrid Bondingは、TSMCのSoICと同じく、接触面を極めて平滑にして分子間力で接続する方式だ
これによりμBumpがなくなる分高さを削減できるし、ついでに言えばμBumpを使った時より電気抵抗も下げられる。加えてダイ同士を極めて高密度に接触させられるので、熱抵抗も下がることになる。
実際高さが減じられたうえ、画像右にあるように熱抵抗も15~30%削減できるとしている。欠点としては、ダイを削る(右下のHCB Process flowで言えばDishingの部分)際に従来より極めて平滑度を上げる必要性がある。おそらくHybrid Bondingに対応できる新しい研磨装置と研磨材料が必要になるので、そこにコストがかかることと、その後にHybrid Bondingならではの工程が入ることだろう。
ただすでにHybrid BondingはTSMC以外にも多くの前工程/後工程企業が手掛けているので、これから手順を開発するほど手間がかかる技術ではない。わりと現実的に実用化は可能かと思われる。
ということで昨今のDRAMの進む方向性を簡単に説明した。足元では引き続きDDR5を始めとしたDRAMの入手難が続き、ついにビデオカードが入手困難、発売中止などいろいろ影響は出ているが、これはあくまでも一過性の話であり、その対応とは別に各DRAMメーカーは将来を見据えていろいろ水面下でやっている、という話である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












