



「Oracle CloudWorld 2024」の主要な新発表を“3つの戦略”でまとめる
分散クラウドからソブリンAIへ、“先行他社とは違う”オラクルOCIの戦略とは
2024年10月18日 11時00分更新

AIインフラ:13万個のNVIDIA Blackwell GPU搭載クラスタが登場へ
OCIが注力する2つめの戦略「AIインフラ」について、シャガラジャン氏は「OCIでは大きく6つのイノベーションを実現した」と説明する。

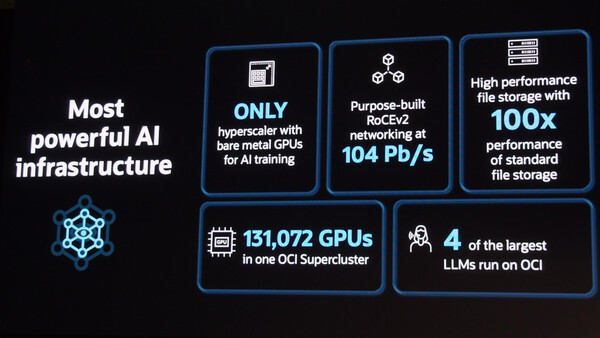
OCIのAIインフラにおける6つの特徴
たとえば昨年のOCWでは、大量の「NVIDIA H100」GPUを搭載したベアメタルマシンを、高速なRDMA(RoCEv2)ネットワークで接続した「OCI Supercluster」を発表していた。巨大な規模のLLMを開発するAIベンダーでは、このSuperclusterを複数セット利用するケースもあるという。
今回は、このOCI Superclusterのスケールをさらに拡大する発表が行われた。単一のクラスタで、最大13万1072個の「NVIDIA Blackwell」GPUを搭載し、2.4ゼタFLOPSのピーク性能を実現するというものだ。オラクルでは、ゼタスケールのAIコンピューティングクラスタは「世界初」だとアピールしている。
なお、GPUサーバーのスケール拡大に合わせて、ネットワーク、オブジェクト/ファイルストレージについても、よりハイパフォーマンスなものがラインアップに追加されている。また、中規模/小規模のAIワークロード向けに「NVIDIA H200」「同 L40S」を搭載したベアメタルインスタンスの提供も発表されている。
OCI Supercluster/AIインフラの特徴

OCIがラインアップするAI向けGPUインスタンスの一覧
シャガラジャン氏は、すでにUberやxAI、Palantir、Cohereといった多数の顧客企業やAIスタートアップが、OCIのAIインフラ/Superclusterを採用していることを紹介した。現在提供されている最大規模のLLMのうち4つが、OCIのAIインフラを利用して実行されているという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
クラウド
オラクルとAWSが「Oracle Database@AWS」発表、AzureやGoogleに続く“分散クラウド”提携 -
クラウド
AWS CEOがオラクル年次イベントの基調講演に登壇、「Oracle Database@AWS」を語る -
クラウド
最小3ラックで自社DCに“専用リージョン”設置、オラクルOCI「Dedicated Region25」発表 -
Team Leaders
NetSuiteが年次イベントで見せた“オラクルとの関係深化とシナジー” - この連載の一覧へ



