




「安全性」の担保に力を入れて設計
Imagen 3は「安全性」の担保をするために、かなり力を入れて設計されています。プレスリリースでは「データおよびモデルの開発から生産に至るまで、最新の安全性と責任に関するイノベーションを駆使して構築」したとしています。同様の記述は8月の技術解説論文にも説明されています。
グーグルは生成AIによる有害なコンテンツの生成を禁止する原理(Principle)を決めているのですが、Imagen 3もそれに従っているとしています。プライバシー保護と暴力、ヘイト、露骨な性描写、過剰な性描写といった有害な出力の最小化を確実にするためのプロダクション・フィルタリングや、誤報リスクを減らすための電子透かしの適応をしているとしています。
また、同程度に「公平性」を重視しているとも述べられています。あいまいなプロンプトからシーンを生成するプロセスで、その画像に偏りをどう生まないようにするかという問題です。特に人物の出現分布に注意をはらっているとしており、「知覚される年齢、性別、肌色の分布に基づく自動化された測定基準により、公平性を評価する」としています。具体例としては、「性別に関係なく医師や看護師になれる」ということを的確に画像に反映するようなことが目指されており、ステレオタイプなイメージが生み出されないようにしているようです。
この過剰とまで感じられる制限は意図的に掛けられています。表現の自由さよりも、グーグルの生成AIについての原則が優先しているためです。利用時には、こうしたグーグルの設計の意図を読み取って、プロンプトを組み立てることで、的確な画像を生み出しやすくなると考えられます。
一方で不思議なのは、「RX-78 gundam」とプロンプトを指定すると、かなり正確なガンダムの画像が出てくるという点です。アニメというよりも、プラモデルの画像を学習したと感じられるような画像なのですが、IPに対するコンテンツフィルターは人物に比べると現状は厳しくないようです。
技術論文の中で興味を引くのが、約3000人あまりの人間が画像の品質を評価した結果です。Imagen 3が特に優秀なのは、テキストプロンプトに対する追従性。Stable Diffusion 3やMidjourney、DALL-E 3などに比べても上だとしています。一方、敗北を認めているのは「絵的な魅力」で、Midjourney v6.0には若干劣るとしています。
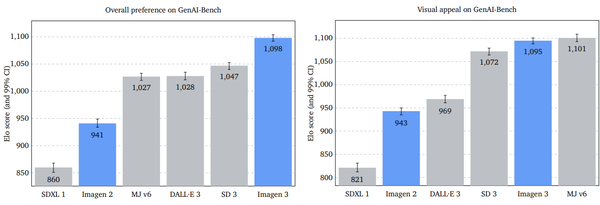
(左)プロンプトによる画像生成の評価比較(「Imagen 3」 P.4)、(右)画像の魅力(「Imagen 3」 P.7)
Imagen 3がどんなトレーニングをしているのかは不明で、論文では「私たちのモデルは、画像、テキスト、関連するアノテーションを含む大規模なデータセットで訓練されています」としています。グーグルは以前から、どのようなデータセットを使い、どのような方法で学習を進めたのかということを、ほとんど公開していません。データは、「品質と安全性の基準を確保するために、複数段階のフィルタリングプロセスを採用しています。このプロセスは、危険、不適切、または低品質な画像の除去から始まります。その後、AI生成画像を排除し、モデルがこれらの画像に特有のアーティファクトやバイアスを学習するのを防ぎます」という説明がなされており、データをふるいにかけたうえで学習させていることはわかるものの、その詳細の説明はなく、これほど高性能な画像が、どのような技術に支えられているのかは、よくわからないという状況です。
この連載の記事
-
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に -
第139回
AI
AIフェイクはここまで来た 自分の顔で試して分かった“違和感”と恐怖 -
第138回
AI
数百万人が使う“AI彼女”アプリ「SillyTavern」が面白い -
第137回
AI
画像生成AI「Nano Banana Pro」で判明した“ストーリーボード革命” - この連載の一覧へ





とは")

















の1台が今ならオトク!")
























")

