




正体がわからないメモリーサイドキャッシュ
メモリーバスの利用率を下げるらしいのだが……
さてそのメモリー帯域の低さを補うためのもの、と思いそうだが正体がわからないのが、Pコアの左に位置するメモリーサイドキャッシュである。インテル自身が明確に説明を避けているのがこれまた謎なのだが、一つ使い方として説明されているのが、メディアエンジンと組み合わせて利用することで、メモリーバスの利用率を下げるというものだ。
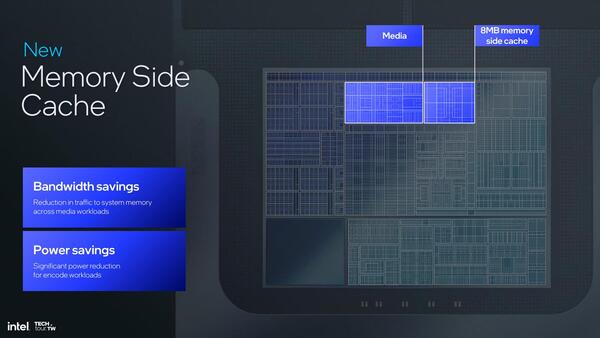
このスライドで、容量が8MBであることが初めてわかったという
メディアエンコードの場合、現フレームと前フレーム、場合によってはもっと前のフレームの画像を比較して差分を取る、という作業が煩雑に行なわれるのでメモリーバスへの負荷は高い。が、手前にキャッシュがあればその中で処理が完結する。当然メモリーバスを利用するより消費電力は下げられるし、メモリーバスを利用する帯域も減らせることになる。ただ、これだけのためにメモリーサイドキャッシュを搭載するというのは考えにくい。
話を戻すと、COMPUTEXにおけるGelsinger CEOの基調講演で示されたスライドが下の画像であるが、これだけではなにを目的としてメモリーサイドキャッシュを搭載しているのかさっぱり理解できない。
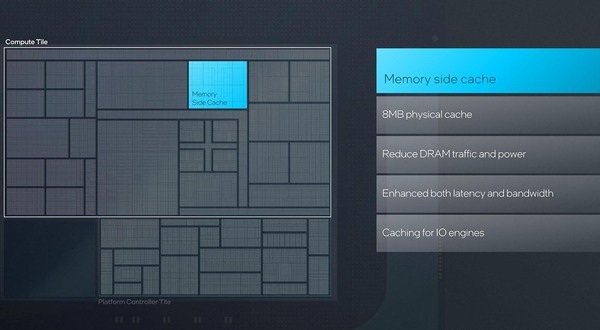
"Reduce DRAM traffic and power"は上の画像の使い方を指しているのだろうが、その下の2つがこのままだと不明である
ところがこの後で下のスライドが出てきたことで、ある程度メモリーサイドキャッシュの目的がクリアになってきた。
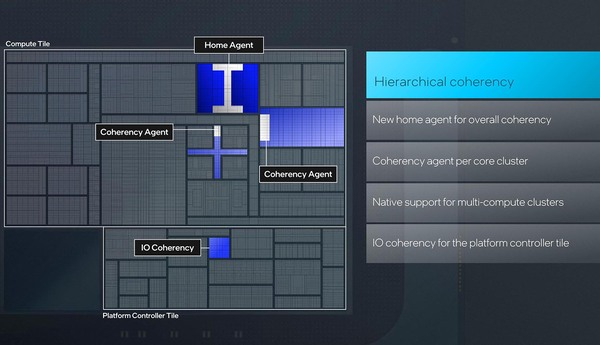
メモリーサイドキャッシュの中にHome Agentがあり、ここがシステム全体のキャッシュ・コヒーレンシーを司る格好になる
そもそもマルチコアCPUのシステムでは、キャッシュ・コヒーレンシーが重要になる。CPU #1とCPU #2がそれぞれ抱えているキャッシュの情報が異なっていた場合、データの不整合が起きるからだ。したがって、あるCPUがキャッシュの内容を書き換えたら、それを他のCPUに伝える必要がある。
正確に言えばあるメモリーの領域を(キャッシュ経由で)書き換える際には、他のCPUに対して「そのメモリー領域のキャッシュ情報を破棄すべし」と伝えるわけである。幸いにもPコア同士、あるいはEコア同士で言えば、そもそも共通の3次ないし2次キャッシュがあるので、ここでコヒーレンシーを担保しているが、問題はPコアとEコアの間のコヒーレンシーである。
当然これはPコアの3次キャッシュとEコアの2次キャッシュが、なにか書き換えを行なうたびにそれを相手に通知するという形でコヒーレンシーを確保していたが、これは効率が悪い。そこでであるが、おそらくメモリーサイドキャッシュは以下の2つの目的に利用されている。
(1) Snoop Cache:どちらかのコアがキャッシュを書き換えた際に、それをもう片方のコアに通知すると、それを受け取った側は自身がそのアドレスをキャッシュしているかどうか確認することになるが、それは無駄が多すぎる。これは特にコア数の大きなXeonでは大問題であり、そこでSnoop Filterというものが登場した。
最初に実装されたのはIntel 5000Xで、この時は実装に問題があってSnoop Filterを使うとむしろ遅くなったのだが、その後改良されており、Xeon Scalableは全製品Snoop FilterをCPU内部に搭載している。
メモリーサイドキャッシュの8MBのウチのある程度(キャッシュの内容そのものを保持するのではなく、タグ情報だけなので、トータルしても1MB程度で済むだろう)がSnoop Filter用に割り当てられていると考えられる。
これを利用することで、例えばあるPコアがあるアドレスに書き込みをしても、そのアドレスの内容をEコアがキャッシュ内に持っていなければ、別にその情報をEコアに送る必要がなくなる。これによりEコアが無駄にキャッシュをチェックする必要もなくなるし、NOCのトラフィックも減ることになる。
(2) Write Back Cache:例えばあるPコアがデータをあるアドレスのメモリーに書き込むと、それはPコアの3次キャッシュ経由でメモリーに書き出される。そして通知を受けたEコアは、自分のキャッシュからそのアドレスの内容を排除した上で、書き出した新しい内容を読み込むことになるが、これをいちいちメモリーから読み出すのは無駄が多い。
書き出す内容はいったんページサイドメモリーに補完し、Eコアはそこから読み出すようにすることで無駄なメモリー読み込みを省ける。
もう一つ考えられるのは、待機時の対応である。稼働時はともかく、待機時になると積極的にブロックごとパワーゲーティングで電力をカットして消費電力を下げる、というのはインテルのプロセッサーでは長らくの伝統である。
Lunar Lakeの場合Eコアの性能がかなり上がっているので、特にバッテリー動作の時などは煩雑にPコアが電力カットの対象になりそうである。
ここで問題になるのは、Pコアを丸ごとカットしてしまうと、復帰に時間がかかることだ。特に12MBもの3次キャッシュの内容を、そのたびごとにメモリーに格納したり、そこから復帰させるのは時間もかかれば消費電力も増えやすい。
そこで、復帰の際に必要になる分だけはメモリーサイドキャッシュに移動させておき、ここだけ電力を供給しておけば、Pコアが電源オフから復帰する際も素早くキャッシュの内容を復元できるし、メモリーバスを使わない分消費電力も下がる。
もちろん、これはPコアだけでなくEコアも対象だろう(例えばメディアエンジンを使って動画の再生中などは、Pコア/Eコア共に電源オフ状態になっていることが考えられる。ここでマウスとかが操作されたら、まずEコアを素早く復帰させる必要があり、この際にもメモリーサイドキャッシュから内容を復元できれば効果的と思われる。
Meteor LakeではLP Eコアがあったから、このLP Eコアだけ動かすことでこのあたりの問題を解決していたが、Lunar LakeではLP Eコアが省かれた関係で、こうした工夫で待機状態からの復帰を高速化するという効果が期待できると思われる。
最初に説明したメディアエンジンの話以外は筆者の推定ではあるのだが、それほど外れていないと考えている。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






































