




前回はLunar Lakeのプロセスとタイル構造で話が終わってしまったので、今回はもう少し内部の話をしよう。
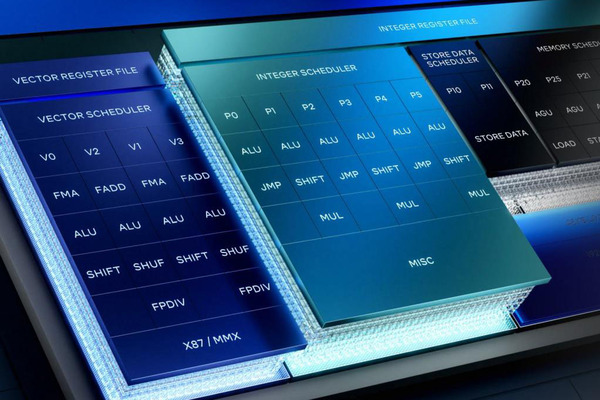
Lunar LakeはPコア4つとEコア4つの珍しい組み合わせ
まずは一番の要であるプロセッサーの構造である。Lunar LakeもPコアとEコアの組み合わせであり、その意味ではAlder Lake(Lakefield)以降で採用されているハイブリッド・テクノロジーを継承した構成である。ただそれが4+4という構成なのはやや珍しい。
もちろん技術的には可能であるのだが、Eコアが4つというのは、これまでの同社のプロセッサーからするとかなり少ないように感じる。おそらくはであるのだが、1つには次回説明するようにEコアの性能が大幅に上がり、性能的にバランスが取れると判断されたのかもしれないし、Eコアを8つにすると面積的に厳しかったのかもしれない。
だったらPコアの数を2つに減らせば良かったようにも思うのだが、ハイパースレッディングなしでの2コアはコア数というか同時処理スレッド数が不足すると判断されたのかもしれない。なんというか、微妙なバランスを取った構成になっている。
またMeteor Lakeで搭載されたI/Oタイル上のLow Power EコアはLunar Lakeでは省かれている。その代わりというべきか、EコアそのものがLow Power Configurationで構成されている。N6プロセス上のLP Eコアより、N3BのLP Eコアの方が消費電力が少なかったのかもしれない。結果としてパワーマネジメント系はMeteor Lakeとまったく異なるものになっている。
そのあたりの話はいずれ話をするとして、まずはPコアとEコアについて。今回PコアはLion Cove、EコアはSkymontと呼ばれるコアがそれぞれ採用されているが、このLion Cove/Skymont共に、従来のコアから大幅に中身が変わっている。
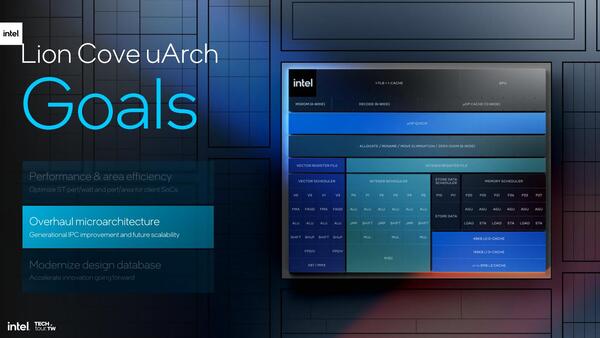
Lion Coveは"アーキテクチャーのオーバーホール"とされるが、オーバーホールというよりも性能の大幅強化という感じではある。もっともオーバーホールらしいところもある
Alder LakeのGolden CoveからMeteor LakeのRedwood Coveまでは基本同一コアで Golden Cove→Raptor Cove(L2:1.25MB→2MB)→Golden Cove(L1 I-Cache:32KB→64KB) とキャッシュサイズの増量が主要な違い(細かなアップデートは除く)でしかない。
ということで、Alder Lakeに搭載されたGolden CoveとLion Coveを比較すると下表のように、猛烈に強化されているのがわかる。
| Golden CoveとLion Coveの比較 | ||||||
|---|---|---|---|---|---|---|
| Decode | 6 wide→8 wide | |||||
| MicroCode | 2 wide→4 wide | |||||
| μOp Cache | 9 wide→12 wide | |||||
| Issue | 12 port→18 port | |||||
| ALU | 5 wide→6 wide | |||||
| FPU | 3 wide→4 wide | |||||
もう少し細かく見てみよう。まずフロントエンドであるがDecodeは1サイクルあたり8 x86命令を処理可能であり、μOp Cacheは最大12 wideまで拡張されている。以前の説明が正しければ、1つのx86命令は1つないし2つのμOpに分解されるので、μOp Cacheは最低でもx86換算で6命令/サイクル、平均しておそらく9命令/サイクル程度の供給が可能になると思われる。

現状ではμOp Cacheのエントリー数は未発表である。ただスループットが1.33倍になっている以上、容量もそれに合わせて大型化されている可能性が高い
次にIssue Port周りだが、そもそもポートの数が大幅に増やされ、かつ同時発行命令が増えたことに対応して内部バッファの容量(ROBやInstruction Windowなど)も増量されている。

In-Flight Windowはもう少し大型化しているかと思ったが、逆に言えば(主にポートが埋まっていることで)今までフルに使いきれていなかったのかもしれない
実行ユニットに関して言えば、Golden CoveではPort 00/01/05をIntegerとVectorで共用、という形になっていたが今回これが分離された。これがスループット向上につながるか? というと、短期的にはNoである。

Power Savingが今ひとつピンとこないのだが、あるいはポート単位でのパワーコントロールをしているとすればあり得る話である
例えばAVX命令などで計算を行ない、その結果を格納するような処理では以下の形で処理される。
Vector→ALU→Vector→ALU→...
Vectorの処理が終わるまでALUが動くことはない。これはVectorの結果を取り込む、あるいは次の計算のためのパラメーターをレジスターにセットするから、Vectorの処理が終わってからでないと意味がないからで、ポートを共用していても別にそこがボトルネックになるわけではないし、ポートを分けても並列度が上がることはない。
しかし、これスケジューラーの方からすれば1つのポートにALUとVectorがつながっているのはスケジューリングが複雑になるだけだし、スライドにもあるように将来の拡張性を考えたらポートを分離した方が良い、という判断になったものと思われる。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






































