



ロードマップでわかる!当世プロセッサー事情 第737回
Sierra Forestの内部構造はGracemontとほぼ変わらない インテル CPUロードマップ
2023年09月18日 12時00分更新

Sierra Forestは144コアのチップレット構造
Alder Lake/Raptor LakeではEコアは4コアでクラスターを構成していたが、Sierra Forestでは2/4コアでクラスター(インテル用語ではコアタイル)を構成する。
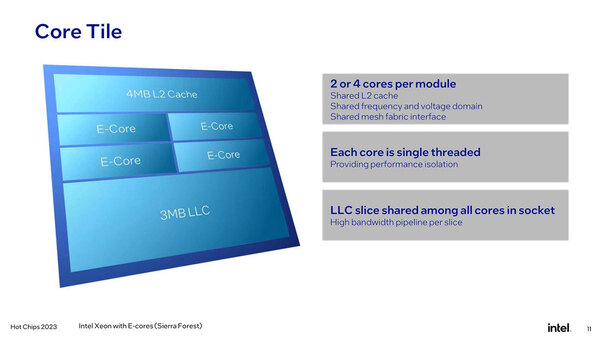
Sierra Forestの構成。インテルはタイルという用語をあちこちで流用しすぎな気がする
3次キャッシュの容量は3MBで、これはAlder Lake世代から特に変わっていない。3次キャッシュより2次キャッシュの方が大きいという容量の逆転現象はまだ解消しないままであるが、そもそもSierra Forestはクラウド・ワークロードなどに向けたプロセッサーなので、3次キャッシュをガンガン使うような大量のデータを扱う処理というよりも、2次キャッシュで収まるような範囲の小さな処理を短時間で済ませる用途(マイクロサービスなどがこの好例だろう)に適しており、この構成で問題ないのかもしれない。
問題はこれがどう構成されるかである。Sierra ForestもGranite Rapids同様にチップレット構造になることが明らかになっている。
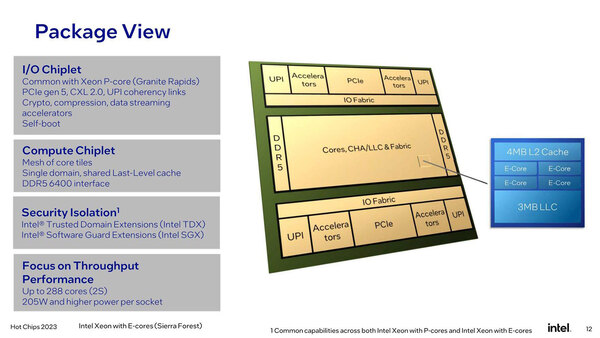
問題はこのコンピュート・チップレットがいくつで構成されるかである
共通、という話はGranite Rapidsのスライドにも出てきた話なので別に違和感はないし、IOチップレットやその先のアクセラレーター類はGranite Rapidsと共通というのも納得できる。そもそもGranite Rapidsとソケットが共通になっているので、このあたりは当然であろう。
ただ上の画像ではまるで巨大なコンピュート・チップレットが1つに見えなくもないが、そんな無茶な構成があり得るのか? を少し考えてみた。
まず最初にGranite Rapidsだが、コンピュート・チップレットが3つで構成されており、かつまだ正確なコア数は公式には不明だが、すでに132コアという情報が流れている。
そこでこれが正しいと考えた場合、構成は下図のようなものになる(最大構成の場合)。
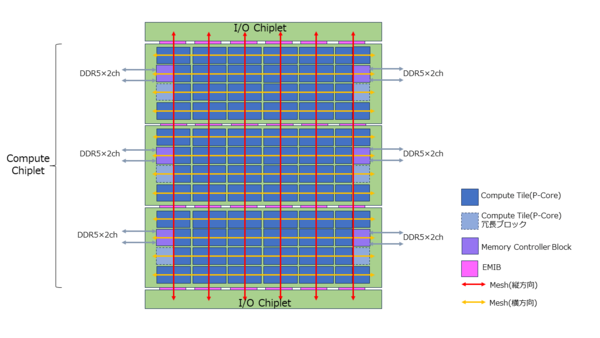
Granite Rapidsの構成図
132÷4=44なので、コンピュート・チップレットあたり44コアである。4×11構成が妥当なところであるが、これとは別にメモリー・コントローラーも2つ(4ch)搭載されることがわかっているので、46ブロック分が入ることになる。
次で計算するように、かなりチップレットのダイサイズは大きくなるので、歩留まり改善のために2コア分の冗長ブロックがあるとするとトータル48ブロック。形状から言って12×4ブロック構成とするのが自然だろう。
Sapphire Rapidsの構成を見ても、横方向のメッシュは全部のブロックを貫通するように構成され、一方縦方向は2ブロックごとに1本配される。すると、132コアの最大構成では3つのコンピュート・チップレットを6本の縦方向メッシュで貫く形になる。チップレット間の接続はEMIBと思われる。
問題はGranite Rapidsにあるコンピュート・チップレットの大きさである。連載736回でも説明したように、プロセスの微細化によりサイズが小さくなるが、3次キャッシュをコアあたり4MBと大きくしたことで、この微細化の効果が半減していると考えらえ、おそらくは700mm2ほどの寸法になると考えられる。
では同じようにSierra Forestの構成も推定してみよう。こちらは144コアとわかっており、かつ4コアごとにタイルを構成するので36タイルと推定される。わからないのがメモリーのチャンネル数である。連載736回のスライドでは、以下のようになっている。
- 3コンピュート・タイルの構成のみ12ch
- 1あるいは2コンピュート・タイルでは8ch
メモリーコントローラーのブロックで言えばそれぞれ6個と4個である。ということは、仮に1チップレットの場合では40ブロックになる。これはやや中途半端な数字であるのだが、前掲したGranite Rapidsの構成図を見ると2チップレットの場合と1チップレットの場合ではチップレットの横幅が異なっている。
つまり1チップレットの場合は縦方向6本のメッシュの全部を使っていない可能性がある。こうなってくると10×4、もしくは8×5のブロック構成の可能性が出てくる。下図が10×4、さらにその下の図が8×5の場合の推定図でどちらもあり得そうではあるのだが、前掲のスライドに近いのは8×5ブロックの方だろう。

10×4ブロック構成の推定図
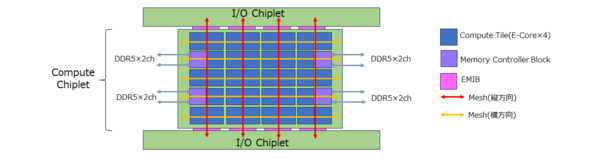
8×5ブロック構成の推定図
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















