




生成AIの弱点は学習に要する高額な電気代
AIプロセッサーの市場が広がるのか? という問いの答えは明白だろう。今年に入って急速に盛り上がった生成AI、具体的に言えばChatGPTやStable Diffusionは、すでにASCII.jpでも大量の記事があがっているし、使われている読者も多いはずだ。
ただ個人的にはこれらはバズワードに感じられるし、おそらく今年後半はハイプサイクルで言うところの幻滅期に入り始める気がする。なぜバズワードか? というと例えばChatGPTで言えば、特定の分野(一部のプログラミングやすでにある文章の要約、書き直しなど)に関してはきちんと効果がある一方、その他の専門的分野の助けにはならないというか、平気で嘘をつくあたり、本格的に使うにはいろいろ難があるためだ。
最近、アメリカのある弁護士が裁判所への答弁文章をChatGTPを使って作成したところ、その文章の中で架空の訴訟が引用されており、結果その弁護士に5000ドルの罰金が下されたという事例もあったりする。理由はいろいろあるが、GPTを専門分野に適用するには、きちんと学習をさせる必要があると筆者は考える。
上の例ではないが、裁判所への答弁文章を作成させるのなら、前段階として憲法や刑法/民法は元より省令の類や過去の裁判の判例まできちんと学習させる必要がある。少なくとも人間の場合、ただの人が判事なり弁護士になるためには、そうした学習をしたうえで試験に合格し、さらに実務経験を積む必要がある。
これはGPTも同じで、そうした学習をさせないで答弁文章を作成させるというのは、弁護士でもなんでもない人に答弁文章を作成させるのと同じことであり、それは嘘も入るだろう。
だからといって、OpenAIに法律文章を全部学習させろ、と要求するのにも無理がある。その学習に要するコストは半端ないからだ。マイクロソフトがGTP-3の学習を行なうにあたり、10000基のNVIDIA V100を14.8日間ブン回し、消費したエネルギー量は1287MWhだった、という報告がある。日本で同じことをしたとすると、1KWhの電気代がだいたい31円(*1)なので、電気代だけで4000万円ほどかかる計算になる。
電気代だけでこれだから、OpenAIのサービスを使って学習させようとすると、さらに値段が上がるのは間違いない。ちなみにこれはパラメーター数が1750億個のGTP-3の場合である。GPT-4のパラメーター数は公表されていないが、一説によれば10倍(1兆7500億個)だそうで、V100のままでは学習に要する電気代が軽く億を超える計算だ。
法律、医療、工学など、さまざな分野でGPTは役に立ちそうな可能性はあるが、それが役に立つためにはその分野の学習が必要であり、それには膨大な電気代が必要になるという壁が立ちはだかっている。
これはStable Diffusionも同じである。こちらも学習次第で絵柄や表現が大きく変化するのは既知の話で、将来的には「お話を入れるとそれに合わせた挿絵を自動生成してくれる」なんてことも可能かもしれないが、そのためにはまだまだ果てしない学習が必要になる。
こうした学習のネックになるのは、性能/消費電力と性能/コストである。例えば性能を変えずに消費電力が100分の1になれば、GTP-4の学習に要する電気代が400万円程度になる。これはビジネス用途次第では支払い可能な金額だろう。ただ、現実問題としてそんな都合の良いソリューションは存在しない。
この分野でNVIDIAのGPUが広く使われているのは言うまでもない。なにしろほとんどのネットワークはCUDAで記述されており、CUDAが動くのは「原則として」NVIDIAのGPUのみである。原則として、というのはSYCLを利用してCUDAを他のプラットフォームで動かす実装は現に存在しており、インテルのGPUやXilinxのFPGA上で稼働している。
またAMDはROCmでCUDAをHIP(C++ Heterogeneous-Compute Interface for Portability)に変換するためのhipifyと呼ばれるツールを提供しており、これを利用することでCUDAのコードを稼働させられるとしている。ただ6月30日にMosaicMLが発表した実験結果(CUDAで記述されたLLMを、AMDと共同でAMD Instinct MI250上に移植する)は下の画像のとおり。
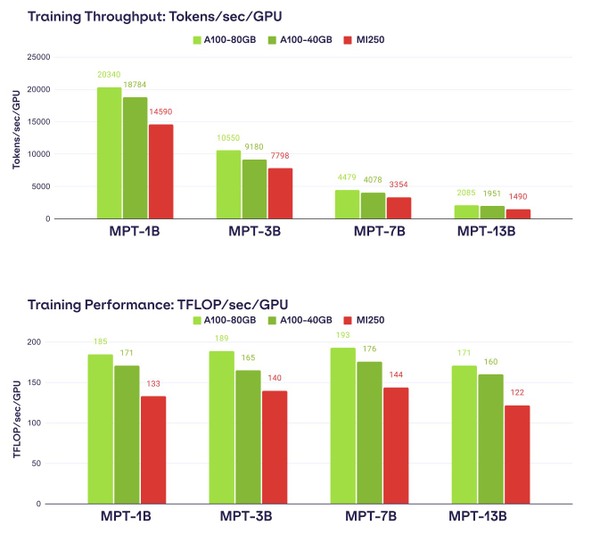
発表に掲載されたスライド。実を言うと、特にチューニングなしでCUDAをROCm経由で稼働させた場合、結果が1桁違うことも珍しくないそうで、そう考えればかなり健闘したと言える
A100 vs Instinct MI250で、カード単体ではむしろMI250の方が性能は上なのに、実際に動かすとA100の方が高速、という結果になっている。これはMosaicMLとAMDが共同でチューニングした結果であり、そう考えるとCUDAでネットワークが記述され続ける限りは、NVIDIAのGPUを利用するのが一番賢明ということになる。
(*1) 公益社団法人 全国家庭電気製品公正取引協議会が2022年7月22日に改定した数字による。ちなみに以前は27円、2014年以前は22円だった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ












ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












