




SDXLの公式DiscordのStable Foundation。「bot」となっているところにプロンプトを入力することで画像が生成できる。一度に1枚しか生成できないが、現在は無料
Stability AIは6月26日、画像生成AIの最新モデル「Stable Diffusion XL」を発表しました(「画像生成AI『Stable Diffusion』最高性能の新モデル『SDXL 0.9』一般的なPCで実行可能」)。パラメーター数がオリジナルのStable Diffusionの9億から23億へと大幅に拡大され、描写力が飛躍的に上昇したモデルです。正式版のSDXL 1.0が7月18日に公開予定とあり、あらためて注目されています。ベータ版にあたるSDXL 0.9は先行して、有料課金サービス「DreamStudio」と、Discordでの公開を開始していました。Discordでは1人無料で1回出力可能で、いまもリアルタイムで生成画像が見える状態です。その後SDXL 0.9は研究用に公開されて、ダウンロード可能になりました。
大きな違いは「2回生成する」こと
SDXLがこれまでのStable Diffusionの仕組みと決定的に違うのは、1回の画像生成で2回生成するプロセスを取っていることです。
プロンプトが画像として生成されるデータセットが「ベース(Base)」と「リファイナー(Refiner)」の2種類に分かれるんですね。なぜこんなやり方をするかというと、2種類のクリップ(画像とテキストとの紐付けのこと)で学習をさせているようなんです。一度、プロンプトを通じてデータセットで生成した画像データを、さらに別のデータセットを使って精度を上げていくという仕組みになっています。

SDXL動作プロセス解説図。入力されたテキストプロンプトは、ベースで一度生成された後、リファイナーでふたたびその画像と組み合わされ、同じプロンプトで再度生成される(Stability AIの説明より)

ComfyUIを使って作成したSDXLのサンプル例。左側がベースで、右側がリファイナーで生成された画像(記事中の生成画像はすべてSDXL 0.9で筆者作成)
実際に、10日にいち早くSDXLに対応した「ComfyUI」というアプリでSDXL 0.9を動かしてみました。ComfyUIはノードベースのGUIに特徴があり、生成を処理する手順を、割と自由に設計できるところに特徴があります。オープンソースで開発が続けられており、Stable Diffusionを動かす有力なアプリの一つです。
ComfyUIではどのように作業が進むのかを見ることができるのですが、生成が開始されると入力したプロンプトが、2つのサンプラー(生成機)に送られます。最初のサンプラーがベース(Base)と呼ばれるデータセットを使って、一度画像を生成して出力した後、もう一つのサンプラーから、リファイナー(Refiner)に入れて、画質を引き上げる仕組みになっていることがわかります。画像の基本サイズも512×512ピクセルから1024×1024ピクセルに大きくなりました。
ただし、そのぶん生成のために要求するスペックが上がっていて、NVIDIA GeForce RTX 20シリーズ以上、ビデオメモリー8GB以上が環境として求められます。
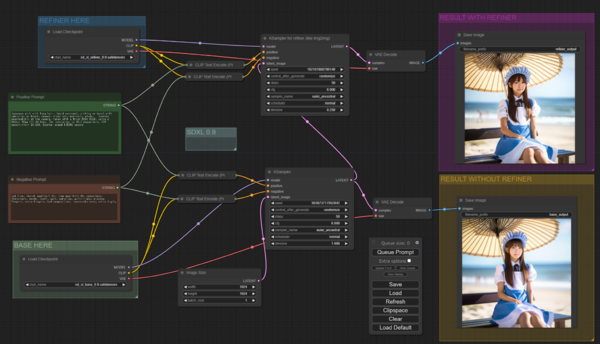
ComfyUIの画面。SDXLが処理できるように設定されている。右下にベースが出力され、右上にリファイナーが出力される
出力できる画像の幅は大幅に広がっていることはすぐに実感できます。たとえば猫とか、ジャングルを進む探検隊、香港の未来の町並み、ブロンズに金の液体をかける……といった思いつく限りの単語を適当に英訳してプロンプトにしてみたのですが、過去のものとは違い、複雑なプロンプトを組まなくても様々な画風が出てきました。特に学習データに偏りがあったと言われるv1.5で出てこなかった東洋人風の顔や、いわゆるアニメ風の二次元の画像もかなり出してくれます。これは相当様々なテクニックが探索されることになるのではないかと思えます。

SDXL作例。適当に文章を作って、英訳してプロンプトにするだけで、かなり複雑な絵が出てくる。実写風からアニメ風まで出力の幅も広い
ただ、指はやっぱりぐちゃっとするんですよね。技術レポートでも明確に書かれていましたが、やっぱり「指問題」は解決が難しいと。「微細なディテールの合成に特化した、さらなるスケーリングとトレーニング技術の必要性を示唆」しているとしており、原因については「手や類似の物体が写真に非常に高いばらつきで写り、その場合にモデルが実際の3D形状や物理的限界の知識を抽出することが困難であることが考えられる」としていました。このあたりはv1.5でも広がったControlNetなどを使うといった、別のテクニックで補うことになる気がしますね。

指が失敗している作例
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")















