




東京大学大学院工学系研究科、松尾研究室は8月18日、日英2ヵ国語に対応した100億パラメーターサイズの大規模言語モデル(LLM)「Weblab-10B」を開発したことを発表、オープンソース(商用利用は不可)で公開した。
言語間の知識転移を活用

生成されたテキストのサンプル
LLMは通常インターネットから収集した大量のテキストデータを使って学習をするが、多くは英語のテキストであり、それ以外(日本語など)のテキストデータを大量収集することには限界がある。
本モデルは日本語だけではなく、英語のデータセットも学習に用いることで学習データサイズを拡張し、言語間の知識転移を行うことで日本語の精度を高めたという。
学習に使用したデータセットは、事前学習に代表的な英語のデータセット「The Pile」および日本語のデータセット「Japanese-mC4」を使用。事後学習(ファインチューニング)には、「Alpaca(英語)」「Alpaca(日本語訳)」「Flan 2021(英語)」「Flan CoT(英語)」「Flan Dialog(英語)」の5つのデータセットを使用した。
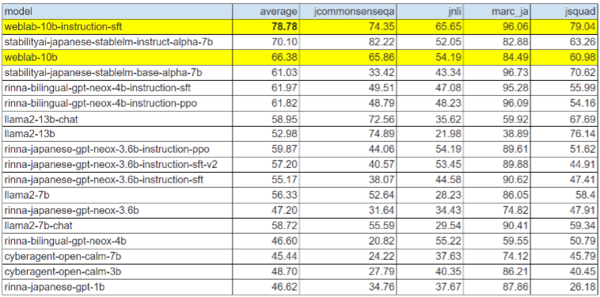
オープンソースモデル性能比較
事後学習の日本語データ比率が低いにも関わらず、日本語のベンチマークが事前学習時と比べて大幅に改善(66>78%)し、言語間の知識転移を確認。この精度は「国内オープンソースモデルとしては最高水準」だという。
同研究所は今後も、「Weblab-10Bのさらなる大規模化を進めるとともに、この資源を元に、LLMの産業実装に向けた研究を推進」していくという。
なお、日本語に特化したオープンソースのLLMは5月にサイバーエージェント、7月には東大発AIスタートアップのLightblue、8月にはLINE、Stability AI Japanと相次いで発表されており、どれも商用利用が可能となっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
