




前回は、EUVでも普通に露光できるのは5nm世代まで、という話をした。今回は、ダブルパターニングとSculptaという新技法を解説しよう。
ちなみにTSMCはN5のプロセスジオメトリー(Contact Poly PitchやFin Pitchなど)を一切説明しておらず、ただN7世代と比較するとSRAMセル(HD:High Density)の寸法が0.78倍(0.021μm)になった、という数字のみを発表している。幸いにSamsungの5nm世代(5LPP:現在はSF5という名称になっている)の数字は公開されている。
| Samsung 5nm世代のプロセスジオメトリー | ||||||
|---|---|---|---|---|---|---|
| Contact Poly Pitch | 60nm(HP)/54nm(HD) | |||||
| Fin Pitch | 27nm | |||||
| M0 Pitch | 36nm | |||||
下の画像と比較してもらうとおおむねIntel 7に近いが、FinやM0はもう少し密度が高いという程度で、Intel 4にはやはりおよばないことがわかる。フィンの間隔などはそろそろEUVのシングルパターニングの限界に近いことがわかる。

インテルの22nmと14nmのピッチサイズ比較
そしてTSMCで言えばN3、Samsungで言えば旧3GAE(3nm GAA Early:現在はSF3A)以降、インテルのIntel 4以降ではもうシングルパターニングでは限界に達している。そこでダブルパターニングが登場することになった。
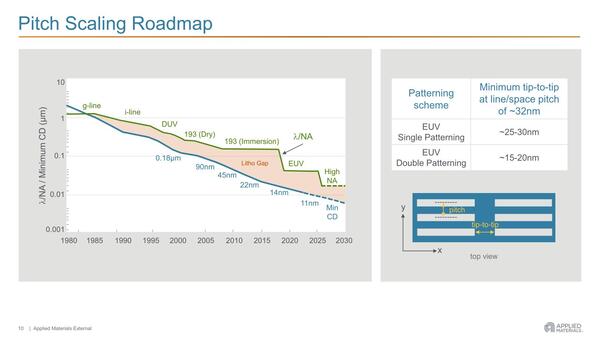
ここからはApplied Materialsの発表資料より。右の図で青が配線がある場所、白は配線がない場所である。2組のフィンの間隔が、シングルパターニングでは最小25~30nmなのに対し、ダブルパターニングでは15~20nmまで縮められるとする
EUV露光を2回実行する
ダブルパターニング
具体的にどうするか? であるが、例えば上の画像にも出てきた上下方向に並ぶフィンを貫くように縦方向に配線を構築するというケースでは、以下の工程で実装することになる。
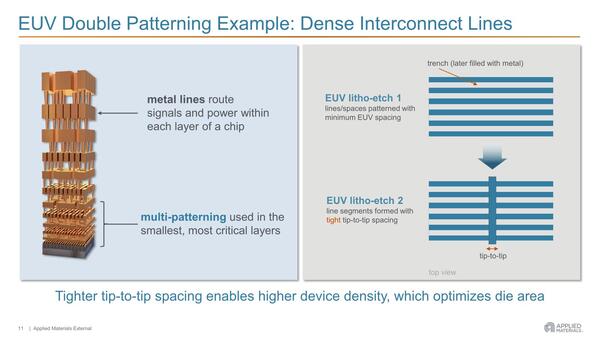
ダブルパターニングの例。チップ間の間隔が狭くなるためデバイス密度が高くなり、ダイ領域が最適化される。これは主に下部の配線層(M0~M3あたり)で重要になってくる技術である
(1) まずフィンを最初のEUV露光→エッチングで構築する。縦方向の配線は考えない。
(2) エッチングした溝を一旦金属で埋める。
(3) 2度目のEUV露光→エッチングで、今度は縦方向の溝を作る。
(4) (2)で埋めた余分な金属を取り除く。
これは穴を掘る場合も同じだ。DRAMやフラッシュでは深い穴を掘る必要があるが、それとは別にロジック向けでもVIA(貫通電極)向けに穴を構築する必要がしばしばある。
これはトランジスタと配線層、あるいは配線層同士の接続に使われるし、最近ではチップ同士の3D積層(AMDの3D V-Cacheなどこの最右翼だ)には膨大な数のTSV(シリコン貫通電極)が使われるから、高密度の穴開けが要求されることもある(*1)。
ただしEUVのシングルパターニングでは穴の直径はともかく、穴の間隔をそれほど詰められなかった。そこでダブルパターニングで2回に分けて穴を開けることで密度を高める方策がとられていた。要するに以下の工程になるわだ。
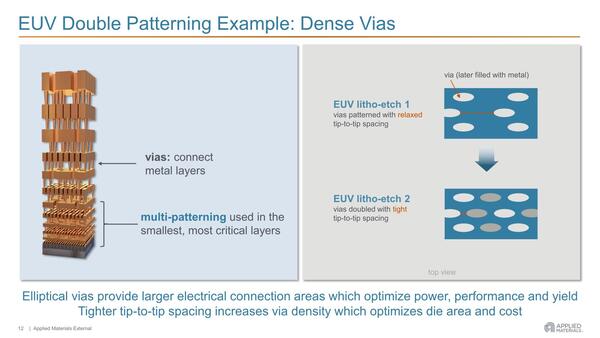
ダブルパターニングの例。楕円形の穴は、より大きな電気接続領域を提供し、性能と歩留まりを最適化する。こちらも同じく、下部の配線層で重要になる
(1) まず白い穴を最初のEUV露光→エッチングで空ける。
(2) エッチングした溝を一旦金属で埋める。
(3) 2度目のEUV露光→エッチングで、今度は灰色の穴を空ける。
(4) (2)で埋めた余分な金属を取り除く。
この方式の問題はいろいろある。まず2回のEUV露光→エッチングの際に位置のずれがあると、それでアウトである。ダブルパターニングはArF(フッ化アルゴン)時代にはさんざん行なわれていた技術であるが、透過式マスクと反射式マスクではやり方が違うし、位置合わせの精度はArF時代よりもさらに厳しい。
またEUV露光を2回実施するので、それだけ消費電力(や薬品類)の消費も大きく、スループットもそれだけ落ちる。ということはウェハーコストの増大につながるわけだ。1回のダブルパターニングあたりおおむね70ドル程製造コストが上がる、というのがApplied Materialsの試算であるが、このダブルパターニングをどれだけする必要があるのか? というのが次の問題だ。
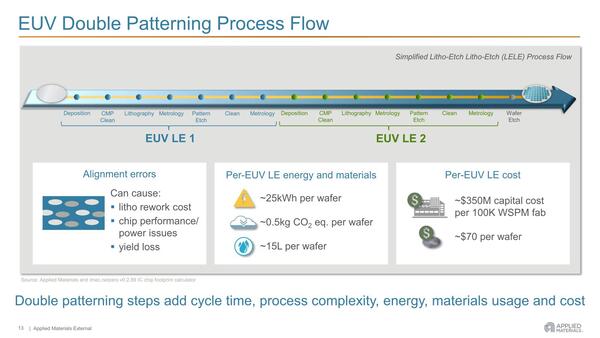
スループットに関しては、もうEUV露光機の数を増やすしか手が無いわけで、ざっくり言えばシングルパターニングの場合の倍の数のEUV露光機が必要になる。ただそこまでやってもリードタイムが倍になることそのものは変わらない
例えばTSMCのN3の場合、25回のEUV露光が必要で、しかもそのほとんどがダブルパターニングだった。ということは、仮に20回だとしても1400ドルほど原価が上がることになる。
N3Eは露光を19回に減らし、しかもシングルパターニングで済むようにプロセスジオメトリーを変更したことで、大幅に製造難易度とコストを下げたことで広く採用されるようになったことを考えると、できればEUVのダブルパターニングは避けたいという意向が働くのは無理もない。
ただN3Eはともかく、今後登場する予定のTSMCのN3P/N3X/N2やSamsungのSF3(旧3GAP:2024年量産開始予定)、Intel 3/20A/18Aなどではダブルパターニングの利用は避けられないと見られていた。
(*1) 3D積層用のTSVは、現在は双方のダイの熱などに起因する歪みに対応する「遊び」を確保するために、あまり高密度での実装にはなっていない。ただ今はともかく今後も密度が低いままか? というのはまた別の話である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























