
レイトレーシングが1.8倍高速化
最後にレイトレーシング周りについて。今回、劇的に性能が向上した的な話は残念ながらなしである。とは言え、細かく改良がなされている。まずカリング(視点から見えないポリゴンをレンダリングしない高速化技術)周りで言えば、RDNA 2のLate CullingからRDNA 3ではEarly Subtree Cullingに切り替わっている。

カリングの手法が変更された。ジオメトリーフラグをハードウェアで管理することで、必要な命令数を15%程度節約できたとしている。ただこれがどの程度性能向上に貢献するかはよくわからない
要するに、レイトレーシングをかける前に不要な計算を省こうという話である。他のオブジェクトの影に隠れて描画されないオブジェクトの計算をやっても仕方がないから、という話だ(厳密に言えばそうでもないのだが、これは描画品質と速度のバーターということになる)。
また複数のオブジェクトのレイの計算順序を変えられるようになった。これによって、シーンに応じて最適な(つまり高速な)処理が可能になる。

レイの計算順序。赤が画面全体、緑が小さなオブジェクト、青が大きなオブジェクトである。従来はClosest First(視点から近い順に処理)が原則だった
加えて、レイの計算順序の最適化やスタック管理の最適化、さらにキャッシュの増量などの効果により、トータルで1.8倍に高速化されたとしている。

レイトレーシングが1.8倍に高速化。ただレイ・アクセラレーターそのものはCUあたり1つのまま変わらない
もっとも、元のRDNA 2のレイトレーシング性能そのものは競合のGeForce RTX 3000シリーズに比べるとかなり見劣りするもので、それが1.8倍になってもまだ厳しいところはある。実際、ベンチマーク結果で言えば下の画像のとおり。

レイトレーシングを使ってプレイしたければ、FSRは必須という感じだ
FSRを無効化した状態での性能向上率はResident Evil Villageで43.6%、Dying Light 2で100%、Cyberpunk 2077で61.5%、Hitman 3で65.2%と素晴らしいのだが、生の数字で言えばResident Evil Village以外は20~30fps台でややプレイ云々以前のレベルである。
FSRを併用すればご覧のように60fpsを超えたフレームレートが実現されているが、まだGeForce RTX 4000に追いつくのは遠いと考えた方が良さそうである。
ハードウェア周りで言えばもう1つ、動画のエンコーダー/デコーダーの話がある。こちらはあまりDeep Diveでも詳細は語られなかったので、KTU氏のレポート以上の情報はないのだが、プレイ動画の配信をH.264からAV1に変更するとどうなるか? という実例で示されたのが下の画像である。こうなってくるとエンコーダーソフトの対応が待ち遠しいところである。
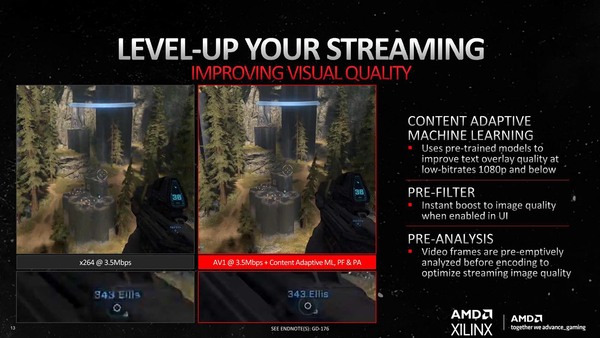
おそらくここのPre-FilterとPre-Analysisが、Xilinx由来のものだと思われる
ソフトウェア周りなどに関しては今回説明を割愛するが、なにか劇的に新しいものが用意されたわけではない。FSR 3に関しても現時点ではプレビューのみで、具体的な実装方法などは不明なままである。
このあたりは製品発売日である12月13日以降に、もう少し情報が出てくるかもしれない(可能性で言えば、来年のCESで実際のゲームに組み込んだデモが行なわれ、その後でもう少し詳細が出てくるという確率の方が高そうだが)。とりあえずはRadeon RX 7900 XT/XTXのベンチマークが待ち遠しいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













