
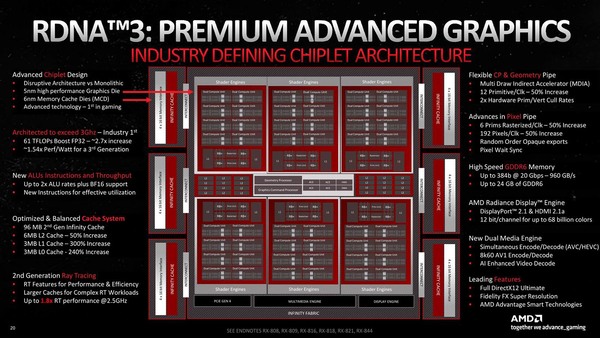
前回に引き続き、RDNA 3の内部解説を説明しよう。今回は内部構造の話である。下の画像がNavi 31の内部構造の全景である。比較対象のために、Navi 21の内部構造をその下に掲載する。
他にもL0/L1は大幅に増量されており、これらの効果でインフィニティ・キャッシュの減量(128MB→96MB)があっても十分性能を維持できたということはありそうである

こちらはNavi 21の内部構造
このレベルで見て判る違いは以下のとおりだ。
- Shader Engineが4→6へ強化。ただし1つのShader Engineに含まれるCUの数は10→8に減った。
- 2次キャッシュが4MB(256KB×16way)から6MB(256KB×24way)に増量
PCI Expressに関しては、Gen 5は不要と判断した(実際純粋なGPUとして使う限りにおいてはGen 4で十分である)とのこと。またCXLにも未対応だそうだが、これも別に不思議ではない。
さて、CUあたりの性能が倍になった、という話はRadeon RX 7000シリーズの発表記事でも触れられているが、その詳細が下の画像だ。

“Compute Unit Pair”という新たな用語を生み出しているが、要するにRDNA 2で導入されたWGPのことである。初代RDNAにはなかった概念だからあえてWGPと書かなかったのかもしれない
わかりづらいが、2つのCUでScalar CacheやShader Instruction Cache、Shared Memoryを共有しているという話で、ここは初代RDNAとまったく一緒である。
異なるのは演算ユニットの数である。RDNA/RDNA 2では1サイクルあたり2つの32-Wide SIMDが動作していた。そもそもGCNの世代はWave 64(64 Threadの塊)に対して、4つの16-Wide SIMDが同時に動作することで、1サイクルで1 Wave 64の処理を行なう形になっていた。
これがRDNA/RDNA 2ではWave 32(32スレッドの塊)に分割され、そのWave 32を32-wide SIMDで処理する格好になっていた。RDNA/RDNA 2ではこの32-wide SIMDがCUあたり2つ搭載されており、1サイクルあたりWave 32を2つ、つまりWave 64を1つと同じ処理性能になっていた。
RDNA 3では、このWave 32を1サイクルあたり4つ処理できるようになっている。要するにSIMDエンジンが倍増した格好だ。もっとも内部的に見ると、やや複雑な話になっている。
というのは、Wave 64が再び復活しているからだ。SIMDエンジンも64-Wide SIMDになっている。ただしこのSIMDエンジン、1サイクルあたりWave 64を1つ、もしくはWave 32を2つ処理できるようになっており、SIMDエンジンあたりのピーク性能はRDNA 2までと変わらない。したがって内部を見ると、32-Wide SIMDエンジン×2と見えないこともないが、実装としては64-Wide SIMDと考えた方が正しい。

なぜ再びWave 64が復活したかの説明はなかったのだが、やはりアプリケーションによってはWave 64の方が効率的だったということかもしれない
このWave 64とWave 32はさすがに混在できないようで、どちらかで動くことになる。このSIMDエンジンが、上の画像にあるように、1つのCUに2つあるわけで、この結果Wave 64なら2つ、Wave 32なら4つを1サイクルで処理できることになる。
これで性能はRDNA 2世代に比べてきっちり倍である。実際にはCU数も80から96と2割増しになっているわけで、同じ動作周波数だとしてもピーク性能はRDNA 2(というかNavi 21)の2.4倍になる計算だ。他にもあちこち手を入れることで、効率そのものも17.4%向上させたとあり、これを加味すると同一周波数での性能はNavi 21比で2.8倍あまりになる。
ちなみに素朴な疑問としてあったのは「なぜCU数を増加させず、CU内の演算能力を倍増させたか」であるが、これは何人かの人に聞いたものの明確な回答はなかった。
ただMike Mantor氏(Corporate Fellow & Chief GPU Architect)によれば「CU数を倍増させた場合も当然検討したし、他のアプローチも試してみた。その中で(今回の実装が)一番性能が出た」という返答であった。CU数をむやみに増やすとスケジューラーの側が追い付かなかった、というあたりが正直なところなのかもしれない。
なおWGPに関しては引き続き1 WGP=2 CUの関係が維持されているそうで、RDNA 2までの仕組みを大きく変えることなく性能を倍増させるにはCUあたりの性能を引き上げるのが一番楽だった、という可能性もある。
これだけでもわりと性能向上が著しいわけだが、これに加えて新しくDot積の演算エンジンが追加された。2つ前の画像で“AI Matrix Accelerator”と記述されているユニットのことだ。Dot積(Dot Products)はAIプロセッサー連載で何度も出てきているのでおなじみかと思うが、下の画像の右側にその定義が載っている。
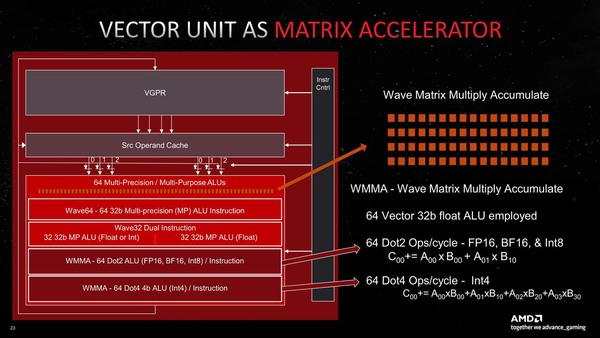
AブロックとBブロックで、アドレスのアクセスの仕方が違う(行列演算ではよくありがち)のがわかるかと思う。このあたりをまとめてやってくれる、つまり複雑なデータ入れ替えの手間が省けるのも性能向上に寄与する
RDNA 3の場合、FP16/BF16/Int 8に対してDot 2(2項目のDot積)が、Int 4に対してはDot 4(4項目のDot積)がそれぞれ実行可能である。どちらも64-Wideになっており、Dot 2の場合は256Flops(1サイクルで乗算と加算をそれぞれ2つ実行するから)、Dot 4の場合は512Flops(同4つ実行)という計算になる。
要するにこれ、NVIDIAのTensor CoreやインテルのXMXと同じような仕組みで、畳み込み演算を高速化するアクセラレーターと考えれば良い。このWMMA(Wave Matrix Multiply Accumulate)の動作を別の図で示したのが下の画像だ。

この図式はTensor Coreなどと大差ない。処理がDot Productsである以上、他にやりようがないというべきか
このDot 2なりDot 4の命令を毎サイクル発行するのは、プログラムの肥大化やスケジューラーの負荷増大につながるわけだが、WMMAでは32サイクルまとめての処理が可能、つまり1回命令を発行すると、32サイクルずーっとDot 2/4の演算を行なってくれるわけであり、この間にプログラムは他の処理をさせることも可能だ。これにより効率的にAI処理が可能、という話になっている。
※お詫びと訂正:RDNA/RDNA 2のWaveに関する記述に誤りがありました。記事を訂正してお詫びします。(2022年11月24日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












