
Shader Model 6.4に対応したAPIを提供
この中でWMMAを直接呼び出す
ところで問題はWMMAをどうやってアプリケーションから使うのか? という話になる。これもいろいろ聞いてみたのだが、将来的にはROCmでサポートする(現在は独自フレームワークを利用するが、それを提供するという話は特に出ていない)など、XDNAでのサポートも「するんじゃないかな」みたいなハッキリしない返事だった。
このあたりはテクニカルライターの西川善司氏と議論したのだが、可能性として一番高そうなのはShader Model 6.4をサポートする形で利用するというものだ。
Shader Model 6.4はDirectX 12以降でサポートされるもので、このShader Model 6も6/6.1/6.2/……とどんどん進化しているし、すでに6.5のアナウンスもあるのだが、ポイントとなるのはShader Model 6.4ではまさしくWMMAが提供するようなDot 2/Dot 4のAPIが用意されることと、マイクロソフトの提供する機械学習向けフレームワークであるDirectML(Direct Machine Learning)の要件がShader Model 6.4以降となっていることだ。
つまりAMDはドライバーの中で、Shader Model 6.4に対応したAPIを提供し、この中でWMMAを直接呼び出せるようにする。マイクロソフトはDirectMLの中で、このShader Model 6.4対応のdot2add()やdot4add_u8packed()/dot4add_i8packed()を呼び出してAIフレームワークを動かすので、アプリケーションがDirectMLを利用してAI処理を行なう場合には自動的にWMMAが利用される、というわけだ。
NVIDIAの場合は、まだそうしたフレームワークがなにもない時にTensor Coreを実装したから、CUDAの中でそうしたものを全部扱えるようにしたわけだが、AMDやインテルは「すでにAPIがあるから、それを使えば良い」という方針のように思える。
もっともShader Model 6.4をLinuxなど非Windows環境から使う場合もあり得るから、なにもしないで済むわけでもなく、それこそROCmなりXDNAなりでなんらかの対応をする必要はあると思うが、現時点では具体的にどうするかまだ決まっていないために明確な返答が出せない、というあたりに思える。
強力なキャッシュ/メモリー構成
帯域強化で1.5倍のラスタライゼーション性能を実現
さて話を戻すが、演算ユニットの性能が大幅に強化された以上、メモリーアクセス性能もこれに合わせて強化しないと無駄になる。そのあたりもわかったもので、RDNA 3ではなかなか強力なキャッシュ/メモリー構成になっている。下の画像がRDNA 3のキャッシュ/メモリー構成である。
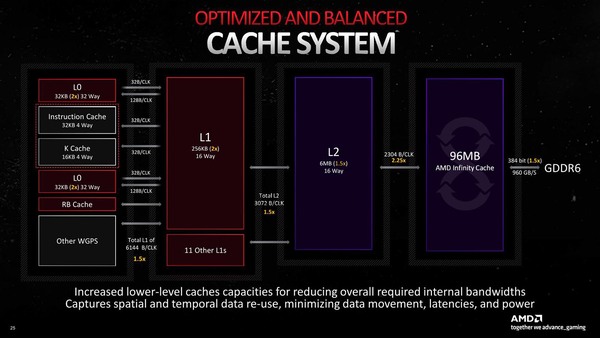
インフィニティ・キャッシュの容量は減っても、帯域が大幅に上がっている&メモリー帯域も増えているから、容量減は大きな問題にならなかった、というのが正確なところかもしれない
比較対象のために、RNDA 2のものを下の画像に示すが、以下のような猛烈な帯域強化が行なわれている。

RDNA 2(Navi 21)の構成。ついでに言えば、RDNA 2では5個のWGPで1つの1次キャッシュを共有していたが、RDNA 3ではこれが4つに減ったので、これも効率向上に効果的な気がする
- 4 Shader Processor→6 Shader Processorになった結果として、1次キャッシュのトータル帯域は4KB/サイクルから6KB/サイクルに強化
- 1次キャッシュと2次キャッシュの間の帯域も2KB/サイクルから3KB/サイクルに強化
- 2次キャッシュとインフィニティ・キャッシュの帯域も1KB/サイクルから2.25KB/サイクルに強化
ちなみに1KB/サイクルというのは、2.5GHz駆動であれば2.5TB/秒に相当するわけで、その帯域の広さがおわかりいただけるかと思う。もちろんメモリーも、RDNA 2のRadeon RX 6950 XTが18Gbps/256bitで576GB/秒だったのに対し、RDNA 3のRadeon RX 7970 XTXは20Gbps/384bitで960GB/秒に達する。倍まではいかないまでも1.67倍に強化されているわけだ。
最終的な描画性能はこのメモリーアクセス性能とROPユニット(ラスタライザー)の性能で決まるわけだが、シェーダーエンジンあたりのラスタライザーの数は32のままのようである。ただシェーダーエンジンの数そのものが1.5倍になったことで、Navi 31はNavi 21の1.5倍のラスタライゼーション性能を実現している。

ほかにもMDIAやCulling(印面処理)の高速化など、細かな部分の改良がされている。前ページにあるCompute Unit Pairの画像に出てきた、CUの17.4%の効率向上の具体的な要素がこちらというわけだ
ということで、ピークの描画性能そのもので言えば、このラスタライザーの性能比の1.5倍ということになる。ただし、ただし、シェーダーエンジンあたりの演算性能そのものは1.6倍になっている計算(CU数は20→16に減っているが、演算性能が倍増)なので、ラスタライザーやメモリー帯域以前に演算処理がボトルネックになっていたようなケースでは、より性能が上がる可能性はあり得る。このあたりは最終的にベンチマークで比較してみないとわからないので、KTU氏に頑張っていただきたいところだ。
AMDが示したベンチマークの結果が下の画像だ。Radeon RX 6950 XT比で言うとRadeon RX 7900 XTXはResident Evil Villageで53.2%、Call of Duty:Modern Warfare 2で51.1%、Cyberpunk 2077で67.4%、Watch Dogs: Legionで47.1%、それぞれフレームレートが向上しているとされる。上の計算がそう間違っていないということであろう。
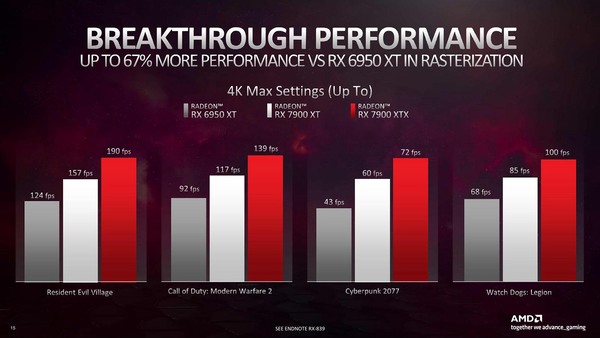
4K最高設定でこれである。それにしても、意外にRadeon RX 7900 XTXとRadeon RX 7900 XTの差が大きい
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













