
Navi 31のGCDはNavi 21から
1割程度の原価アップで済んでいる
ところでTSMCのN6のコストが不明なのだが、仮にN6のコストがN7と同等だったと考えると、製造原価はNavi 21の4割増し程度で収まる計算になる。GCDは原価1.7倍ながら520mm2→300mm2になったことで、製造原価はNavi 21の0.98倍とほぼ同等。MCDは6つで222mm2なので、Navi 21の0.43倍程度だからだ。
ただ実際はこの差はもっと小さいと想像される。というのは、1.7倍という数字は250mm2のダイを試作した場合のコストだからだ。500mm2を超えるダイと300mm2のダイでは、当然歩留まりが異なるわけで、おそらくNavi 31のGCDのコストはNavi 21の90%未満に抑えられているだろう。
もっと歩留まりが高いのはMCDの方で、なにしろ37mm2なので1枚のウェハーから千数百個取れるわけで、歩留まりは当然相当高い。上の試算では1.4倍としたが、このあたりを換算すると実質的な原価はせいぜい1割アップ程度で収まっているだろうと想像される。
もう1つ驚異的なのは、このGCDとMCDの間はシリコン・インターポーザーではなく、オーガニック・パッケージが利用されていることだ。
オーガニック・パッケージを使った例で言えば、IBMが2021年に発表したTelumプロセッサーがやはりオーガニック・パッケージの上に2つのダイを搭載しているが、どうやってシリコン・インターポーザーを使わずに実現したのか? という質問の答えが「すごいがんばった」だったことを記憶している。今回は明らかにTelumより配線数が多いので、相当がんばったと思われる
GCDを複数のチップにするのに比べればマシだったらしいが、それでもMCDを接続するにあたってはGDCとの間に数千本以上の配線が必要になるとしている。
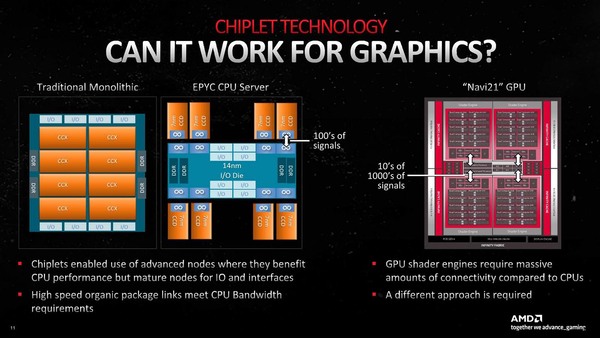
EPYCやRyzenではインフィニティ・ファブリックのリンクがせいぜい数百本のオーダーだが、CU(Compute Unit)と3次キャッシュ(=インフィニティ・ファブリック)のリンクは数万本のオーダーになる。今回も数千本というよりは万のオーダーに近い本数で接続したようだ
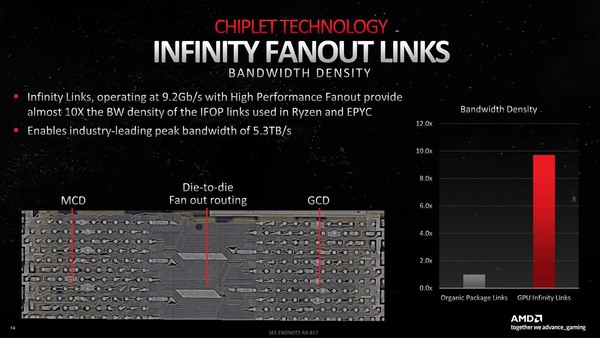
この結果として「シリコン・インターポーザーでは配線密度が足りなかった」(Naffziger氏)という仰天するような返答が返ってきた。下の画像は、通常の配線とNavi 31の配線を、ほぼ同等の縮尺で比較した場合のもので、10倍どころではない配線密度になっているのがわかる。

通常の配線(左側)とNavi 31の配線(右側)。2つ上の画像には配線密度10倍とあるが、実質50倍くらいの配線密度ではないかと考える
そもそもオーガニック・パッケージでは配線密度が足りないのでシリコン・インターポーザーが登場したのに、これでも足りないからオーガニック・パッケージに戻るというのは一見意味不明だが、シリコン・インターポーザーの場合は配線層を複数重ねられない(これも厳密には正確ではなく、可能だが難易度とコストがさらに上がるので、使われていないというのが正確か)。
したがって、数千本/mmの配線層を複数積層して、数万本/mmの配線を実現することは猛烈に難しい。そのくらいなら、オーガニック・パッケージ(こちらは配線層を積層するのは難しくない)を使った方がマシという判断だったらしいが、どちらにしても相当難易度の高い技術である。
このI/FをAMDはインフィニティ・リンクと呼んでいる。また新しいI/F用語が出てきたわけだが、これもNaffziger氏によれば「上位層はインフィニティ・ファブリックであるが、物理層は独自」とのことであった。
実際RyzenやEPYCに利用されているインフィニティ・ファブリックの場合、配線長は最大10mmを超える(Ryzenで20mmくらいだろうか? EPYCは明らかに20mmを超えている)長さで、信号速度は30Gbps前後という構成である。
ただし本数そのものは16対(片方向32本:双方向で64本)と少ない。対してNavi 21の本数そのものは明示されていないが、配線長はせいぜいが1~2mmのオーダーだ。そもそもMCDとGCDが隣接して配されている以上、中央の“Die-to-die Fan out routing”の長さは1mmないと考えられる。
信号速度は、仮に本数が数千本だとすればあまり上げる必要はない。上げなくてもバス幅が広ければ必然的に帯域は確保できるからだ。前述の画像のとおり信号速度は9.2Gbpsとされており、加えて言えば、バス幅を広げて速度を落とすことは、SerDes(Serialize:De-Serialize)が不要ということになり、これはレイテンシー削減に効果がある。
Navi 31のMCDアクセスは、Navi 21のインフィニティ・キャッシュアクセスよりレイテンシーが10%削減できたそうで、それでいてトータルの帯域は5.3TB/秒と猛烈な数字を確保している。これが、Navi 31で猛烈に増えた(ざっくり言えば2倍以上になった)演算能力を支えているわけだ。

Navi 31のMCDアクセスは、Navi 21のインフィニティ・キャッシュアクセスよりレイテンシーを10%削減できる。正確に言えば、同じ動作周波数で動かすと若干レイテンシーは増えるらしいが、動作周波数の向上でその分をカバーしてお釣りが10%ほどあった、ということだそうだ

トータルの帯域は5.3TB/秒。これは当然MCD 6つで5.3TBという話なので、1 MCDあたりで言えば883GB/秒ほど。768bit幅という計算になる。もちろん 信号はディファレンシャルで、送受信は別だろうから都合4倍で3072本。ほかにインフィニティ・キャッシュの制御信号とGDDR6の制御信号の類も要るだろうから、総信号本数は3200本位になるだろう。なるほどシリコン・インターポーザーでは足りなくなっても不思議ではない
※お詫びと訂正:Navi 31のMCDアクセスに関する記述に誤りがありました。記事を訂正してお詫びします。(2023年1月14日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












