




優秀な検索エンジンを搭載
ハードウェアアクセラレーターも複数実装
Cassiniに新たに搭載された機能としては、Hardware List Matchingがある。要するにリストの中から、渡されたデータに当たるものを検索する処理である。HPCではこの処理が結構多いのだが、Cassiniでは最大64億Match/秒という猛烈な検索エンジンが搭載されており、この処理をCPUから完全に分離できるとしている。
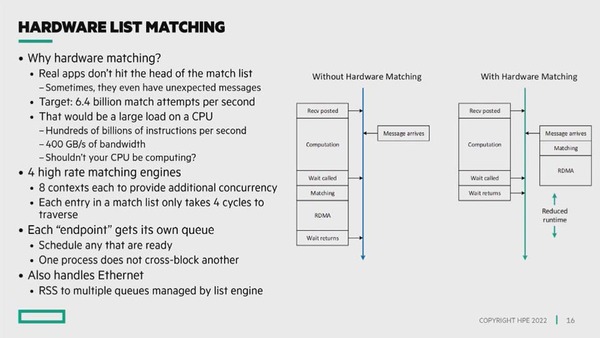
Cassiniに搭載された新機能のHardware List Matching。矢印線の左側がCPU、右側がネットワークカードの処理になる。ちなみにRDNAはConnectX-5にも搭載されている
実際の性能が下の画像だ。左は検索対象数と処理メッセージの数の比較で、おおむね50~60個くらいまでで言えば16プロセッサーで3千万メッセージ/秒程度、48プロセッサーでは8千万メッセージ弱の処理が可能である。右はMPIを使ってのメッセージサイズとメッセージレートの関係で、64Bytesあたりまでほぼ一定(1億メッセージ/秒弱)の処理性能を維持できているのがわかる。
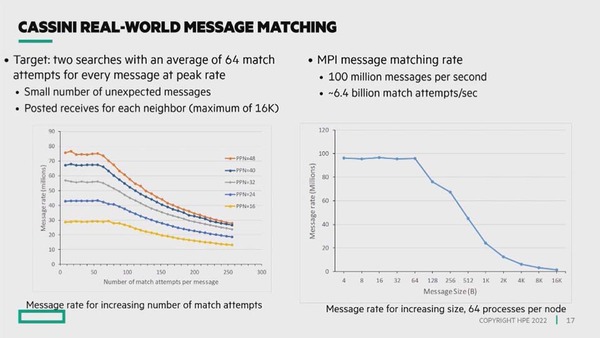
左のPPNはProcessor Per Nodeの意味。検索対象が増えるとどうしても性能が落ちるが、60個くらいまでのマッチングであれば一定のレートを示す
またMPIを使う際に共有メモリーを利用することも多いが、ここでもハードウェアアクセラレーターがいくつか搭載されている。

排他制御に利用できるFENCEやイベントカウンター、Remote flush(リモートノードの共有メモリーエリアの内容を強制書き換え)などをハードウェアでサポートしているのが特徴的
特にFI_MOREオプション(libfabricというライブラリーで提供されているオプション。これが指定されると、ある書き込みリクエストに続く形で追加の書き込みがあることが明示的に示される)を指定した場合、書き込み速度が50%以上上がる(ただし64Bytesまで)といった結果が示されている。これだけの速度でネットワーク経由での読み書きは、通常のイーサネットではやや厳しいところである。
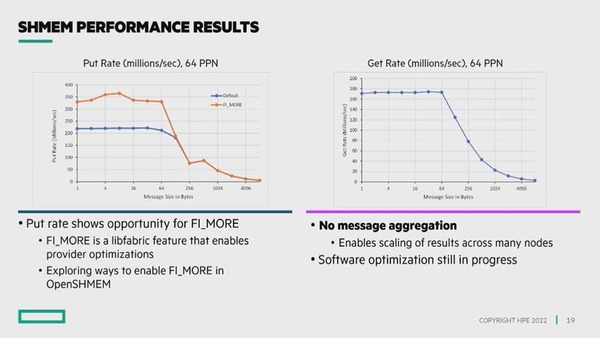
FI_MOREオプションが指定されると書き込み速度が50%以上上がる。左が書き込み(Put)、右が読み出し(Get)。単位は書き込み頻度(100万IO/秒)、構成は64プロセッサー環境だそうである
ネットワークからの通信をトリガーにして処理する機能も提供されており、並列処理を行なう際の自由度の高さをハードウェア的に担保している(凝ったことをしてもハードウェア的に処理されるので遅くならない)ことが特徴である。

ネットワークからの通信をトリガーにして処理する機能。もちろん通常のイーサネットでもMagic Packetみたいなものはあるので、機能が皆無というわけでもないのだが、ここまでの自由度はもちろんない
現在HPEはこれに続き、400Gイーサネット×2となるCassini 2を設計中である。プロセスもTSMCのN7に切り替わるそうで、これは将来のHPC向けに採用されるだろう。ただ、AMDのEl Capitanに間に合うかどうかは微妙なところ。その先を狙ったもの、と考えておいた方が無難だろう。
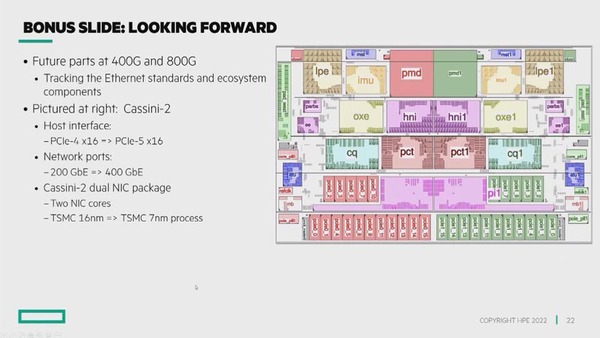
400Gイーサネット×2となるCassini 2を設計中。ただこのままだと現在のRosettaでは間に合わないので、スイッチ側の変更も必要になる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























