




米国時間の8月21日からHot Chips 34がスタートする。今年もいろいろと目玉は多く、AMDがRyzen 6000とInstinct MI200と400G Adaptive SmartNIC SOC、インテルがPonte VecchioとMeteor Lake/Arrow Lake、それにXeon D 1700/2700、NVIDIAがHopper、Glaceに加えNVLink Network Switchの発表を行なう。
他にも、先日紹介したLightmatterが、Passageの説明をするほか、個人的にはBiren TechnologyのBR100 GPGPUやJuniperのExpress 5、ArmのMorello Evaluation Platformなどが気になるところだし、Tesla MotorのDOJOも内容によっては記事で取り上げたいと考えている。
目立たないところで言えば、MediaTekのDimensity 9000もなにげにArmのTotal Compute Solution 2021を代表するSoCの1つであり、これもArmの最近の動向とあわせて紹介してもいいかもしれない。
ということでHot Chipsは業界から注目を集めているイベントであるのだが、その直前の8月17日~19日に、同じIEEEのHot Interconnectsというイベントがあるのは案外に知られていない。参加者数で言えばHot Chipsから一桁落ちるので仕方がないのだが、こちらはインターコネクト関連ならなんでもということで、今年も(筆者的には)非常におもしろいネタがいろいろ出てきている。
CXL 3.0の話や、まだOMIが諦めてない(!)などをはじめ、今年のテーマは“Disaggregation Leading to Reaggregation”(解体と再構築)なのだが、それに沿ってイーサネットのトランシーバーの構成に関する再提案など、なかなか参加していて楽しい話題が多い(こういうのを喜ぶ人があまり多くないのはわかっている)。その中で目を引いたのでご紹介したいのが、HPEによるSlingshotの解説である。

買収に次ぐ買収から生まれた
独自のインターコネクト「Slingshot」
HPE(旧Cray)のSlingshotは、HPCなどの大規模システムの中核をなす独自のインターコネクトである。もともとのCrayはCray-1から始まるベクトルプロセッサーをベースとしたシリーズで、連載275回から連載279回まで説明している。このシリーズを手掛けていたCRIは1996年にSGIに買収される。ただそのSGIも行き詰まり、Cray部門は2000年にTera Computerに売却される。
Tera Computerは独自のMTA-1や後継のMTA-2を開発していたが、Cray部門の買収に合わせて社名をCray Inc.に変更している。この結果として新生Cray Inc.は、SGI時代のMPP(Massive Parallel Processor)とMTAシリーズのSMT+MPP、2種類のスケーラブルなアーキテクチャーに関する一定の知見を蓄積していたと言える。
これが生かされたのが、2002年10月に契約を獲得したASCI RedStormである。このRedStormで、CrayはSeaStar Linkと呼ばれる独自の3次元メッシュのリンクを開発。最終的に1万880個のOpteronをこのSeaStar Linkで接続することで、高い実効性能を叩き出すに至った。
このSeaStar Linkはその後Gemini/Ariesという後継のインターコネクトに進化するが、2012年にCrayはこうした独自インターコネクトのハードウェアとソフトウェアの資産一式、さらにはエンジニアも含めた部門全体をインテルに売却する。
では一体Crayはその後どうしたか? というと、2018年10月末に発表したShastaで、まったく新しいSlingshotインターコネクトを発表する。実はこのShastaを最初に採用したのが、NERSC(国立エネルギー研究科学計算センター)のNERSC-9ことPerlmutterである。
最初のSlingshotであるSlingshot-10は、実はハードウェア的にはイーサネットそのものである。SlingshotのチップはMellanoxのConnectX-5で、2レーンで200Gbpsの帯域を持つ。これと組み合わせるスイッチの方はBroadcomのTomahawk 3というスイッチで、これで64ポート×200Gbpsの容量を持つ。
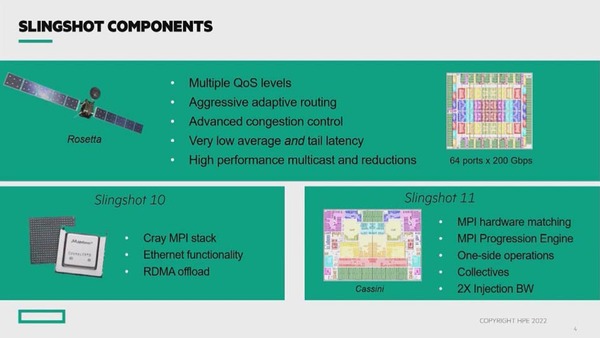
左下のSlingshot 10チップにMellanoxのロゴが入っているのがわかる。Tomahawk 3は、Rosettaという名前になっているが、中身は一緒である
ただし普通のイーサネットとして使うのではなく、HPC向けの独自インターコネクト向けにドライバーおよびその上位のネットワークスタックの最適化を図ったものである。そもそもネットワークトポロジーそのものが独自である。DragonFly Topologyと呼ばれるもので、2008年にJohn Kim博士(現在はKAISTの教授を務めているが、当時の所属は米ノースウェスタン大学だった)らが考案した方式である。Dragonflyの構造を簡単に説明したのが下の画像である。
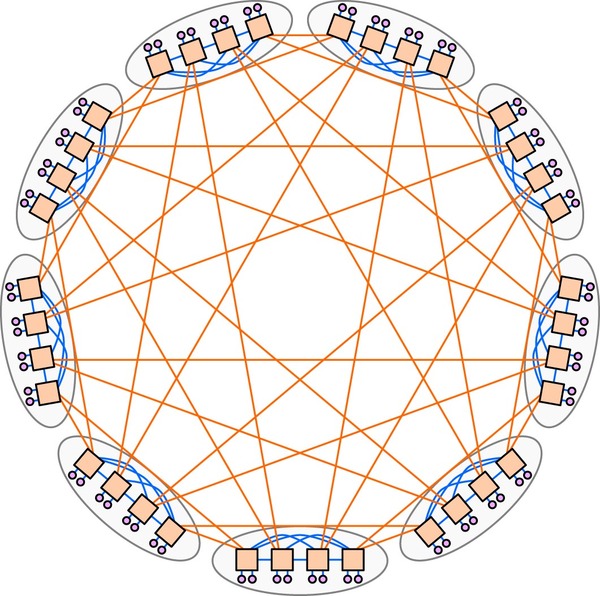
○がノード、□がスイッチというかルーターである。Kim博士の論文の表記に従えば、まず小さなグループ(8ノード/4ルーター)を作るが、ここではすべてのルーターが相互接続されているので、グループ内であれば2ホップでノード同士が通信できることになる。
一方でグループ同士もお互いに相互接続されている。この結果として、グループをまたぐ通信は、最速で2ホップ、最低でも4ホップ、平均で言えば3ホップほどで接続できることになる。
実をいうと、このDragonflyを最初に実装したのは、Ariesの世代である。Ariesの場合、このDragonflyに最適化した特殊なネットワークコントローラーを採用していた。これに対し、Slingshot-10では汎用のイーサネットコントローラーを使っている関係でAriesに比べると多少効率は落ちているが、その代わりにイーサネットとの互換性は高い。Perlmutterでは、このSlingshot-10が利用されたわけだ。
なおNERSCのインターコネクトに、“Each GPU-accelerated compute node in cabinets with Slingshot 10 interconnect fabric is connected to 2 NICs, allowing each node to have 2 injection points into the network. This configuration is sometimes described as dual injection or dual rail. A GPU-accelerated compute node in cabinets with Slingshot 11 fabric is connected to 4 NICs.”とあり、Slingshot-10とSlingshot-11が混在していることがわかる。
またAuroraのプロトタイプ的な位置付けになる、アルゴンヌ国立研究所のPolarisにもSlingshot-10が採用されているが、こちらもSlingshot-11にアップグレード予定とされている。
ということでやっとHot Interconnectsの発表につながる。今回(Crayを買収した)HPEが発表したのは、Slingshot-11である。つまりSlingshot-10の後継となる製品だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












