



ロードマップでわかる!当世プロセッサー事情 第665回
Windowsの顔認証などで利用されているインテルの推論向けコプロセッサー「GNA」 AIプロセッサーの昨今
2022年05月02日 12時00分更新

久々にAIプロセッサーの話だ。今回はIntel GNA(Gaussian mixture model and Neural network Accelerator)の詳細を説明する。今年4月に開催されたLinley Spring Processor Forum 2022で突如インテルはGNAの詳細を説明したからだ。
GNAそのものはIce Lakeの世代で搭載されたという話を連載525回で触れている。このGNA、最初に発表されたのはICASSP 2017なのだが、実はこの際の発表はポスター(論文をベースに発表するのではなく、要点をまとめた物を1枚のポスターにまとめて張り出す)であって、内容もあまり深い話は掲載されていない。

インテルが発表したポスター
この時点で発表された内容をもう少し細かく説明すると、2017年時点で利用されているニューラルネットワークの中では、さまざまな特殊処理が利用されるケースが多いとされていた。具体的にはレイヤーモデル(それぞれの層を構成)では以下のものが使用される。
- affine(アフィン変換)
- diagonal affine(斜交アフィン変換)
- Gaussian mixture model(混合ガウスモデル)
- recurrent(循環)
- convolutional1D(一次元畳み込み)
- transpose(転置行列)
- Interleave/Deinterleave(インターリーブ化/インターリーブ解除)
アクティブファンクションとして以下のものが使われるケースが多い。
- PLW(PieceWise Linear:区分線形関数)
ところが通常のALUやFPUではこれを短いサイクルで実行できる機能はないので、これらのアルゴリズムをプログラムで処理する必要があり、これが非常に時間がかかる。
そこで、こうした処理を専用に受け持つがGNAとなる。構造は下の画像のとおりで、各層の特徴をレイヤー・ディスクリプターに記述しておき、GNAはこれらと必要なデータ、パラメーターを読み込んで、結果を再びメモリーに返すという、典型的なアクセラレーター的な動作を行なう仕組みだ。
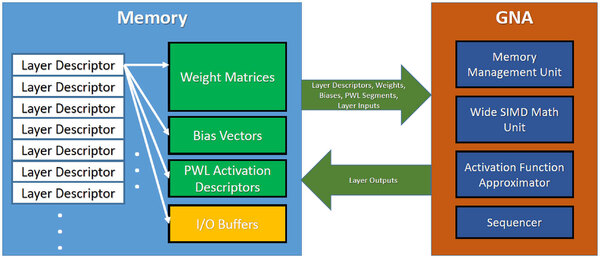
GNAの構造。レイヤー・ディスクリプションやウエイト、バイアスなどを格納するために専用のSRAMが必要となる
使い方もおもしろい。GNAはIntel Deep Learning SDK Deployment ToolやDeep Learning SDK Inference Engineといったツール経由で利用する以外に、GNA native libraryで利用できるとしているのだが、そのGNA native libraryというのが下の画像だ。

こともあろうにIntel Quarkである。おそらくSIMDエンジンとは別に、制御用にQuarkが搭載されていたのだと思うが、なにもQuarkでなくても……。当時手頃なCPUが他になかったのかもしれないが、それにしてもQuarkとは……
久しぶりに黒歴史記事を書きたくなるIntel Quarkが使われており、この上で動くRTOS(リアルタイムOS)向けのAPIと、それとは別にSIMDエンジンを直接叩けるミドルウェアAPIが用意されていたそうで、普通のアプリケーションはこのGNAxxxx()を呼び出して使う形になっていたと思われる。
ポスターでは、このGNAを利用した際の効果として、ビデオ映像にリアルタイムで字幕を付ける処理について、GNAを併用するとCPU負荷が半分になるとしていた。
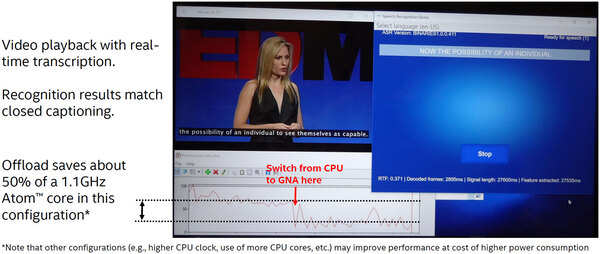
1.1GHzのAtomで100%だった負荷が50%になったという話なので、そもそもそれほど負荷が高くないという考え方もできる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















