ロードマップでわかる!当世プロセッサー事情 第653回
RDNA 3は最大10240SPでRadeon RX 6900 XTを遥かに超える性能 AMD GPUロードマップ
2022年02月07日 12時00分更新

RDNA 3では2つのCUを1つにまとめ
CUの規模が4倍に増加
RDNAはCUを2つ束ねたものを、WGP(Workgroup Processor)として扱っている。このWGP、RDNA/RDNA 2の時点では、ハードウェア的には1つの管理単位であったが、ソフトウェアから見れば2つのCUとして見える形で、少なくとも明示的にWGPレベルでなにか管理、という話ではなかったはずだ。
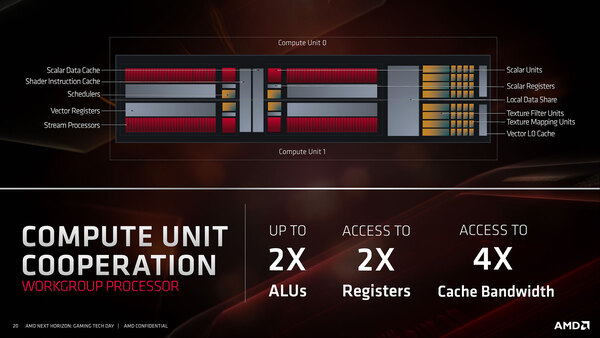
RDNAはCUを2つ束ねたものをWGPとして扱っている。当初からWGPで管理すればよかったのに、と思わなくもない
WGPには共有のローカルデータシェアやスケジューラー・データキャッシュ/スケジューラー・インストラクションキャッシュが配されていたが、5つのWGPで共有される形で128KB L1が配され、さらにその外側の外側にすべてのWGPで共有される形で4MB(256KB×16)のL2が配される形になっている。
このL2の容量はSKU(CU/WGPの数)によって変化する。RDNA 2では、このL2のさらに右側、インフィニティー・ファブリックにインフィニティー・キャッシュがL3として追加実装されているが、ここまでの基本構造は同じと考えていいだろう。

L1の総容量は当然WGPの数で変化するし、L2/L3もこれに合わせて変化すると思われる
ということで、ここでCUが廃されるというのはどういうことかと言えば、スケジューラーやベクトルキャッシュが、2つのCUで共通になるように構成された形で、しかもSP数が倍増するという構成になったと考えられる。

これはRDNAの図を基にした、RDNA 3のWGPの想像図。実際にはベクトル・レジスターの容量も倍増していそうだし、そもそもテクスチャーフィルター/マッピングユニットの数が1WGPあたり8/32個かどうかも疑問が残るところではあるが、想像図なので勘弁してほしい
要するにCUの規模が4倍になった形で、Wave 32を1サイクルあたり8つハンドリングできることになる。これをCUとして表現しなかったのは単に過去のCUとごっちゃになるのを避けたかったためだろうし、なぜ2CUを1つにまとめたかと言えば、おそらく規模を大きくするにあたり、より大きな単位で管理するようにすることでオーバーヘッドを減らしたかったのだろう。
ひょっとすると、Wave32に代わりWave64が管理単位として復活するかもしれないが、それなら32-Wide SIMD×8よりも64-Wide SIMD×4の方が合理的な気がするので、Wave32はそのまま継承されるだろう。
この、SP数が倍増したWGPが5つと、RB(Render Backend)がまとめて1つのL1を共有する、という構造そのものはRDNA 3でも変わらないようだが、RDNA 3ではこのWGP×5+RB+L1をまとめてシェーダー・アレイと呼び、これが最小単位になるらしい。つまり1280SP構成だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













